
Diagnosing Sample Ratio Mismatch in Online Controlled Experiments : A Taxonomy and Rules of Thumb for Practitioners - Aleksander Fabijan, Jayant Gupchup, Somit Gupta, Jeff Omhover, Wen Qin, Lukas Vermeer, Pavel Dmitriev
ABSTRACT
✅ product 일반적으로 온라인 서비스나 플랫폼에서 실험 중인 특정 변경 사항이나 새로운 기능
OCE == A/B TEST는 product 수정 때문에 유저의 행동에 작은 인과관계 변화를 감지할 수 있는 문제를 다루는 표준 운영 절차가 되고 있음.
그러나 OCE는 신뢰성 및 데이터 품질 문제에 민감함.
데이터 품질 문제 중 하나가 SRM고 이는 실험에서 관찰된 샘플 비가 기대와 다른 상황을 의미하며 다양한 증상으로 나타남.
근본 원인(root cause)을 모른 채 SRM을 무시하는 것은 잘못된 product 수정이 양호한 것으로 나타나 유저에게 전달됨.
→ 논문은 4개의 SW 회사, 25개의 product, 1억 유저를 통해 실험을 통해 SRM을 진단하고, 수정하고 쉽게 방지하는 방법을 다룸.
1. INTRODUCTION
가장 단순한 OCE는 product의 두 변형을 랜덤으로 선택된 두 그룹의 유저에게 동시에 노출시킴.
❗ OCE at run Microsoft : MSN의 한 product 팀은 rotating card 수를 12 → 16개로 늘림. 실험 전 기대했던 것은 유저가 클릭하고 참여하는 횟수가 하는 것임.

충분히 작은 변화를 감지하기에 통계적인 검정력을 가졌고, 유저의 상호작용 측정은 정확히 기록되고 모아졌고, 실험을 진행한 플랫폼은 신뢰할 수 있는 분석을 제공했음.
but, 클릭 증가를 보인 관련 실험의 학습에 기반해 기대했던 것과 대조적으로 실험은 card 참여도의 상당한 감소를 드러냄. → 유저가 더 많은 card를 보일 때 click이 줄음.
data quality warning : 실험 변형에서 유저의 예상치 못한 비율이 나타남. 16개의 card가 노출된 treatment group은 더 적은 유저를 가짐. → 이 차이로 SRM 발생
SRM은 OCE의 일반적이고 심각한 데이터 품질 문제를 나타내는 유용한 지표 중 하나임.
SRM이 실험에 바로 나타나는지 검증하는 동안 근본 원인을 발견하는 것은 매우 어려움. 원인은 숙련된 분석가의 deep-dive 분석을 통해 결정함.
이를 방치하면 급속히 이슈가 퍼짐. SRM 조건은 실험 생명주기의 어디든 일어날 수 있음.
→ 논문은 1) SRM을 진단하고, 2) 예시를 통해 확인하고, 3) 감지하여 쉽게 방지하는 방법을 다룸.
2. BACKGROUND
2.1 OCE
✅ treatment vs control
control : 이미 존재하는 시스템
treatment : 새롭게 추가된 feature X를 가지는 시스템
시스템의 유저 상호작용이 기록되고 평가 지표가 계산됨.
실험이 잘 디자인됐고 올바르게 실행한다면, 두 variant 사이의 다른 것은 오직 featrue X일 것임.
외부 요소(계절성, 다른 피처 런칭의 영향, 경쟁 이동)은 균등히 분배됨.
두 그룹 간의 평가 지표 차이는 feature X와 랜덤 기회로 나타날 수 있음.
→ 후자의 가설은 t-test로 검정 가능함.
유저 행동의 변화와 product가 만들어낸 기회 사이에 인과 관계를 만들 수 있음.
2.2 OCE steps
✅ telemetry 원격으로 데이터를 수집하고 전송하는 기술을 의미함. 주로 IT 및 개발 분야에서, 사용자의 행동, 시스템 상태, 성능 지표 등을 자동으로 수집하여 서버나 데이터베이스로 전송하는 데 사용함.
모든 OCE는 여러 단계를 가짐.
- experiment assignment : 유저가 어떤 특별한 기준에 기반해 그룹으로 나눠지고 product 변형 중 하나에 배정되는 초기 단계
- experiment execution : 유저가 초기 배정에 기반하여 변형이 적용되고, 사용이 기록되는 단계
- experiment log processing : 두번째 단계에서 만들어진 telemetry을 유저로부터 모으고 몇몇 브라우저 저장소에서 클라우드 저장소로 업로드해 모으는 단계
- experiment analysis : 처리된 로그가 영향을 받은 유저로 필터링되어 분석되는 단계
2.3 Data Quality
2.3.1 SRM
실험 변형 중에 기대된 유저(실험 시작 전)의 비율과 실험 끝에 관찰된 유저의 실제 비율 간의 차이를 나타내는 데이터 품질 검사
ex. 50/50 split은 두 실험 variant 사이 기대됨. 실험 끝에 각 그룹에 노출된 유저의 수 사이의 비율은 거의 1에 가까워야 함.
→ SRM을 감지하기 위해 카이제곱 검정을 사용할 수 있음. 검정에 사용한 수와 관측된 수 사이의 차이가 발생하면 근본 원인을 조사해야 함.
2.3.2 Diagnosing SRM
트리거 분석은 treatment group와 control group만 분석 과정에 포함되며, 잘못된 트리거 또는 필터링 기준이 SRM 유발할 수 있음.
또는 product telemetry을 수정하거나 실험 변형을 배포하는 시스템, 실험자에 의해서도 발생할 수 있음.
3. RESEARCH METHOD
연구를 위해 qualitative, quantitative 데이터를 모으고 분석함.
이가 결합된 방법론을 사용함.
→ 흔한 SRM 종류를 파악하고 어떻게 진단하고 SRM을 막을 것인지가 목표
4. SRM LEARNINGS AND INSIGHTS
4.1 SRMs are a common data quality issue
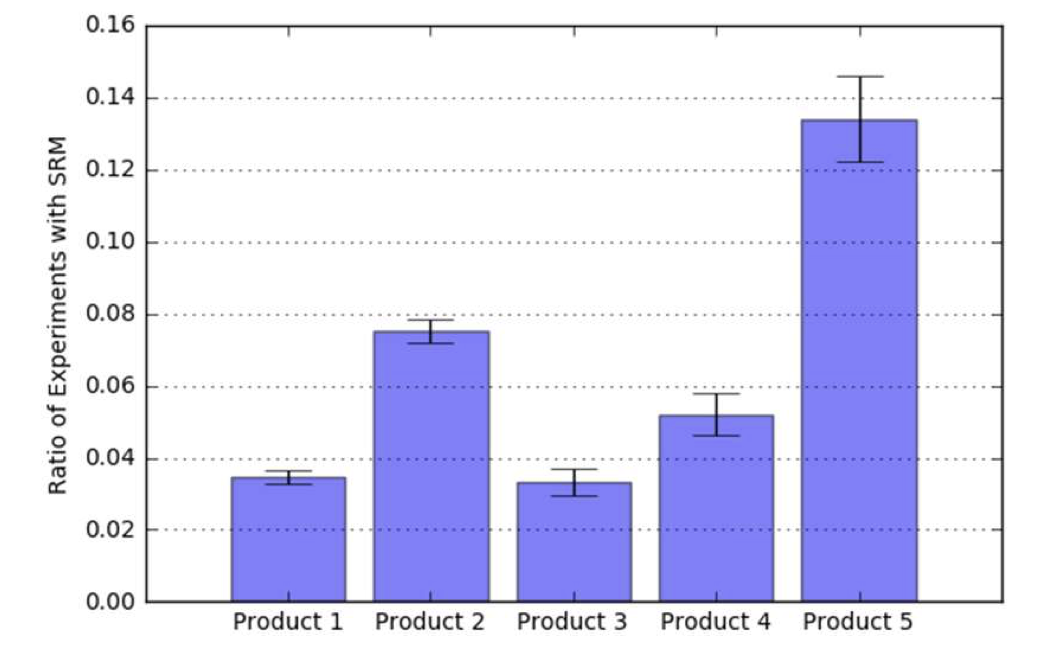
대규모 기업의 연구들에서 SRM은 대규모의 실험에서 흔함을 확인함.
product당 실험 수 기준 내림차순 정렬
→ 1년에 1만개의 실험을 진행하는 product는 적어도 하루에 1번의 SRM이 관측됨.
4.2 SRMs indicate invalid analysis
SRM이 나타나는지, 근본 원인을 주기적으로 확인해야 함. → SRM은 결정적인 의사 전에 발견하고 해결해야 할 중요한 데이터 품질 문제임.
SRM은 실험을 통해 얻어진 인과 추론을 무효화시키는 선택 편향을 야기함.
→ 선택 편향이 있으면, 성능 지표의 변화가 일어나고 처리 효과가 실험에 기여할 수 없게 만듦.
4.3 SRMs are challenging to root-cause
SRM을 관찰하는 데 걸리는 시간, 실험의 구성 요소에 대한 큰 차이를 발견함.
SRM을 진단하는 것은 몇 분에서 몇 달이 소요되며, 실험 설계, 랜덤화 과정, 변형 배포, 데이터 로깅 및 수집, 분석을 위한 여러 조건으로 발생함.
→ 복잡도가 높고, 많은 노력이 필요함.
4.4 SRM indicators make diagnosis effective
단순한 통계 검정은 실험이 SRM을 가지는지 확인하는 데 사용할 수 있으나 근본 원인일지 모르는 실험자에게 충분한 단서를 제공하지는 않음.
→ 실험 시간 또는 유저 개별 세그먼트 단위를 조사하거나 SRM의 근본 원인을 나타내는 주요 지표로 사용할 수 있는 데이터 품질 지표를 만듦.
4.5 Some SRMs can be prevented
SRM를 완전히 막을 순 없으나, 특정 유형은 막을 수 있음.
redirect, filtered condition으로 야기된 SRM은 실험자를 교육함으로써 막을 수 있음.
→ redirection이 필요할 때 웹 페이지의 control, treatment 변형 둘 다 redirect될 수 있음. 그들은 또한 넓은 트리거링 조건을 선택할 수 있고 실험 변동를 제어함으로써 막을 수 있음.
4.6 SRMs can have a positive cause
SRM은 실험 중 여러 문제로 인해 발생하는 반면 몇몇은 긍정적인 treatment 행동 지표가 될 수 있음.
ex. treatment 변형의 로드 속도가 향상될 때 로드 이벤트가 기록될 가능성은 증가함. product에 대한 참여를 증가(treatment 항목이 두 개로 늘어남.)시키면, 이벤트가 기록될 가능성이 증가함.
5. FIVE COMMON TYPE OF SRMs

SRM을 분류함.
5.1 Experiment assignment SRMs
- experiment : A/B TEST는 실험 전에 이전 기간의 결과를 계산하고 유저를 두 그룹으로 랜덤으로 나눠도 주요 지표에 큰 차이를 야기하지 않는지 확인하는 것이 가장 좋음.
- outcome : 실험 할당 서비스에 버그가 드러남. hash function을 사용하여 천 개의 bucket으로 유저를 랜덤 추출했고, 각 bucket은 유저의 0.1%를 나타냄.
- 각 실험에서 실험 소유자는 treatment와 control에 배정되는 버킷의 수를 정의함. 이때, 특정 변형에서 적거나 많은 버킷이 할당됨.
- generalization : 세 가지 요구 사항이 있음.
-
- end user는 변형이 적용될 확률이 동일해야 함. (50-50 split)
- single end user의 반복 할당은 일관성이 있어야 함. 즉, 사용자가 연속적으로 방문할 때 동일한 변형에 할당되어야 함.
- 다수의 실험이 실행될 때 실험 사이의 상관관계가 없어야 함.
-
- detection : 위에서 언급한 요구사항의 위반이 SRM을 야기함.
- 첫번째 조건 위반을 통해 불안정한 user id가 만들어지고 이는 두번째 조건 위반하여 SRM을 야기함. 세번째 조건은 쉽게 인지할 수 없는 더 절묘한 방법으로 위반될 수 있음.
- prevention : 많은 경우 실험 변동 배정은 userID의 hashing을 하는 것임.
- 서로 다른 시드를 사용하는 경우, 해싱 라이브러리는 서로 독립적인 해싱 함수를 사용함.
- 매우 큰 시드 숫자가 있는지 확인하기
- 시간이 지남에 따라 시드 목록을 변경하기
- 두 개의 다른 실험의 변형이 서로 상호작용할 때 독립적으로 랜덤화하는 것은 SRM을 야기할지도 모름.
- 동시에 두 실험에 노출되는 유저가 없게 해야 함. 실험 과제가 서로 배반적이어야 함. → 다른 시간 프레임에 실험을 실행하거나 각각의 실험에 분리된 모집단을 사용함으로써 달성할 수 있음.
5.2 Experiment execution SRMs
- experiment : Skype는 오디오 퀄리티를 향상시키는 목표를 수행함.
- 동적으로 버퍼링 파라미터를 조정하는 것은 오디오 질을 향상시키길 도움. 그러나 다수의 파라미터가 있으면 최적의 세팅은 다양한 네트워크 특징에 의존함.
- treatment 변형은 수신된 오디오의 버퍼링 동작을 세팅하기 위해 contexted-based ML을 사용하고, control은 통화에 사용되는 모든 매개변수를 사용함.
- outcome : 고정 파라미터에 비해 context-aware 파라미터를 사용한 것이 오디오 성능 지표가 향상될 것으로 기대함.
- but, 대조군에 비해 30% 적은 세션을 수집하여 SRM 경고를 받았고, 오디오 왜곡과 playback delay의 상당한 증가를 야기함.
- explanation : Skype 실험의 근본 원인은 세션 중간에 실험 배치를 비동기적으로 새로 고친 것이었음. 업데이트된 배치가 세션 도중 지켜지지 않았지만, 버그로 인해 변형 id를 추적하는 메모리 내 변수가 업데이트됨. 결과, 실험 로그는 부정확한 변형 id를 기록하고 보고함. 30% 로그 정도가 treatment가 시작되지 않은 것처럼 보고됨.
- → 이후, 세션 도중 새로고침이 발생하지 않은 세션인 모집단의 subset을 실험에 사용했음.
- generalization : 근본 원인은 라벨한 SRM 시나리오로 구분됨.
- SRM’s due to variant delivery behavior (다른 시간에 변형이 시작됨.)
- SRM’s due to variant execution behavior (실험 중에만 알 수 있는 복잡한 특징을 기반으로 한 모집단을 타겟하는 지연된 필터 실행 때문)
- SRM due to telemetry generation behavior
- 웹페이지의 모든 변형을 redirecting하지 않는 실험은 일부가 redirection을 실패하여 SRM를 가짐.
- 새로운 telemetry가 product에 추가되면, 적어도 일회성 유저에게 하나의 이벤트를 반환받을 가능성이 증가하여 더 많은 유저가 관찰됨.
- treatment가 product의 성능을 감소시키면 로그를 만들기 전에 유저는 product를 그만두기 위한 더 많은 시간을 가져 SRM가 일어남.
- first run occurrences (첫 번째 실행이 시작될 때)
- 변형이 유저 참여를 증가시키거나, telemetry가 생성되기 전 유저가 종료하거나, 변형에 버그가 있고 충돌하는 경우 SRM이 생김.
- 실험의 결과를 진행하고 보고하기 위해 실험이 실행된 모든 곳에서 telemetry를 수집할 필요가 있음.
- → 실험은 여러 물리적 장치로 실행되어 데이터가 전송중에 중앙 처리 파이프라인에 손실되는 과정에서 SRM이 생길 수 있음.
- detection : 정확한 근본 원인을 진단하는 것은 telemetry loss를 측정하는 데이터 품질 지표나 product 성능 지표(속도 및 신뢰성, 유저의 행동을 측정하는 참여도) 가지는 것임.
- → 이들은 모두 세션 기간과 관련있음을 발견함. 세션이 길수록 구성의 새로고침이 취약함. → 새로고침을 추적해가며, 두 집단의 특징 차이를 사용하는 접근은 SRM의 원인을 고려하는 중요한 단서로 꽤 유용함.
- prevention : telemetry의 신뢰도를 추적하고 control, treatment 변형 사이의 편향을 평가하는 것을 막을 수 있음.
- product의 다른 코드가 실행되기 전, first telemetry signal을 도입해야 함.
- first signal은 데이터 손실의 상황에서 편향된 결과를 만드는 것을 막기 위한 다른 데이터 품질 지표와 함께 사용되어야 함.
5.3 Experiment Log processing SRMs
- experiment : Microsoft에서 12에서 16개로 rotating card의 수를 늘리는 실험으로, 유저의 클릭 수와 참여도가 증가할 것으로 기대됨.
- but, control 실험은 상당한 감소가 나타남. 16개 카드가 노출된 treatment는 SRM 경고가 나타나며 기대보다 더 적은 유저를 가졌음.
- outcome : deep-dive 분석은 데이터 처리동안 treatment의 가장 참여도 높은 유저가 컴퓨터 bot으로 분류되었고 bot 활동을 검사하는 알고리즘에 의해 실험 분석에서 제외됨. 이를 고려해 올바르게 기능하도록 변경함.
- generalization
- 많은 SRM은 데이터를 처리하는 방식으로 발생하며, raw telemetry로부터 다양한 수준(세션 또는 유저)의 요약 통계량이 전달됨.
- → 이를 위해 데이터는 aggregated, join, filter, summarize
- missing data, 잘못된 join이 SRM을 이끌 수 있음.
- → 이러한 문제는 cooking 과정을 반복함으로써 데이터를 복원할 수 있음.그러나 이는 시스템 구조에 달렸고 충분히 오래 raw 데이터가 저장되지 않는 stream 처리 시스템에서는 불가능할 수 있음.
- detection : 두 개 또는 이상의 구별된 데이터 수집 또는 cooking 파이프라인이 있다면 telemetry collection 또는 telemetry cooking 문제와 동일하게 파이프라인에서 복제되지 않음.
- 다른 파이프라인에서 만들어지는 요약 통계량을 비교하면 SRM이 언제 발생할 가능성이 있는지 확인하는 데 도움이 됨. 또, 파이프라인의 서로 다른 부분을 추가로 확인하면 정확한 근본 원인을 잡는 데 도움이 됨.
- 분석에 포함되는 로그 기록의 종류와 크기에 대한 모니터링을 구현하는 것도 도움이 됨.
- prevention : 유저가 로컬 시스템에서 실험에 들어가기 전 treatment로 노출되지 않음을 보장하는 것임.
- 후처리 선택 효과
- treatment 노출 후에 만들어진 데이터를 기반으로 bot를 필터링하는 것은 bot detection 시스템에 사용된 신호에 treatment가 영향을 줄 때 문제가 됨. 따라서 후처리 데이터가 필터링에 사용되지 않음을 보장해야 함.
- ex. 데이터 처리 파이프라인은 실험에 처음 노출되었을 떄 사용자의 속성를 결정하고 이후 변화를 허락하지 않음.
- 후처리 선택 효과
- ex. 자동적으로 유저가 실험에 들어가도록 설계함으로써 그들은 언제 노출되는지 알 수 없음.
5.4 Experiment analysis SRMs
- experiment : First Run Experience(FRE, 사용자가 product를 처음 열었을 때 보이는 이미지) 페이지를 스킵하는 것이 유저 행동에 영향을 주는지 실험함.
- control 유저가 FRE를 봤을 때 발생한 이벤트 또는 treatment가 볼 것으로 예상되는 이벤트를 기반으로 FRE를 본 사용자에 대해 트리거 분석이 적용됨.
- outcome : 트리거된 scorecard에 treatment 변형에 더 많은 유저가 있음. 해당 product의 모든 유저를 포함하는 non-triggered 분석은 SRM이 나타나지 않음.
- explanation : 네트워크 통신을 절약하기 위해 이벤트를 일괄적으로 전송함. 오래된 디자인은 로드가 오래 걸림. control 유저가 더 일찍 그만둠. 오래된 디자인은 가시성을 나타내는 데이터 로그가 손실될 확률이 더 높게 나타남.
- → 트리거 조건이 분석의 대상이 되는 모든 유저를 포괄할 수 없음.
- generalization : 이 단계에서는 telemetry filtering이 주된 근본 원인임. 이는 분석 구성이 잘못되었거나 counterfactual 로깅(treatment에만 기능이 표시, control에는 누락됨.)이 잘못 설정되었기 때문에 발생함. 잘못된 트리거링, 필터링 조건도 일반적인 경우임.
- detection : 트리거링이나 필터링되지 않은 분석에서 SRM이 일어나지 않았다면 근본 원인은 트리거링 또는 필터링 분석 과정에 놓임.
- 로그인 직후 FRE 페이지를 볼 수 있도록 트리거링된 분석에서 유저의 적격성을 결정함.
- 시작점이 SRM를 이끄는지 진단하기 위해 실험 시작으로부터 누적된 표본 크기를 계산하는 방법이 도입됨.
- 처음 유저와 마지막 유저의 SRM 비를 계산하는 것 역시 리텐션 변화의 효과를 확인하는 데 도움이 됨.
- prevention : telemetry filtering SRM을 막기 위해서는 실험 시작부터 분석을 시작하는 것을 추천함. 트리거링 또는 필터링 조건으로 샘플 사이즈를 균형 있게 하기 어렵다면 더 많은 유저가 포함되도록 조건을 완화해라.
- ex. 페이지에서 행동을 하는 유저 대신 페이지를 보는 유저로 분석을 실시해라.
5.5 Experiment interference SRMs
- experiment : Microsoft store 홈페이지, Microsoft 홈페이지의 실험 중 하나에서, 페이지 redesign의 영향을 평가했는데 올바르게 디자인됐음에도 불구하고 SRM을 가짐. 변형은 올바른 데이터를 기록했으며, 다른 근본 원인은 기각됨. 그러나 기대보다 control 변형에 더 많은 유저가 존재했음.
- outcome : deep-dive 분석 후, 실험 변동에 대한 인간 개입을 알게 됨. 몇몇 유저는 변형을 직접적으로 가리키는 URL을 가지는 검색 엔진 캠페인으로 변형들 중 하나에 향해짐.
- → 영향을 받은 유저는 분석에서 분리하고 아닌 유저만 실험 결과에 사용해야 하는데, 대부분은 다시 실행함.
- generalization
- SRMs due to variant interference : 실험 과정에서 실제 최종 사용자 또는 실험자의 관여 때문에 일어남.
- → 검색 엔진 캠페인으로부터 유저를 실험 변형 중 하나로 배치함.
- 많은 product는 디버깅의 목적으로 URL 파라미터 또는 구성된 문자열을 사용해 특정한 변형 경험을 강제하기 위한 숨겨진 방법을 가짐.
- ex. 실험자가 변경을 수행하기 위해 실험 동안 변형 중 하나를 한동안 일시 중지하는 상황, 몇 변형만 강화하는 상황
- SRMs due to telemetry interference : product 변형을 적극적으로 방해하는 경우
- ex. 유저가 telemetry field 중 하나를 통해 injection attack을 만들면서 활동적으로 product telemetry를 조작함. 이것은 심한 SRM를 야기함.
- detection : 실험자 개입으로 인한 SRM를 감지하기 위해 플랫폼을 사용해 활동을 모니터링하고 실험동안 변형이 바뀌는 때마다 알람 설정할 것을 권장함.
- prevention
- 행동의 결과에 대해 실험자에게 알리면서 효과적으로 SRM을 막음.
- interference SRM을 막기 위해 실험자가 특정 네트워크 영역 외부의 변형을 실험 하기 위해 직접적인 할당을 사용하는 것을 막기를 권장함.
- 실험자에게 그들의 결과 알리고, 이상값(blank, injection strings, etc.)을 모으는 telemetry을 모니터링할 것을 권장함.
6. Rules of thumb from SRM investigations
1) examine scorecards
유저의 subsample(트리거/필터링된 scorecard)에서 SRM이 일어나고 실험의 모든 유저가 포함된 표준 scorecard에 SRM이 없다면 실험 분석에 트리거/필터 조건이 잘못되었을 가능성이 있음.
→ 필터 조건을 완화하여 더 많은 유저를 포착하고 SRM 문제가 일어나는 시점을 조사해라.
2) examine time segments
SRM이 오직 하나의 유저 segment에 일어나면 SRM의 원인이 그 segment에 국한될 가능성이 있음.
ex. treatment가 256-bit 암호화와 같은 일부 브라우저에 의존하면 오래된 버전의 브라우저 segment는 SRM을 가질 수 있음.
3) examine time segments
SRM의 증거가 실험 1일차에 강하게 있고 더 오랜 기간이 지난 후에는 SRM을 관찰되지 않으면, 실험 중 캐싱 또는 변형 시작 지연과 같은 시간과 관련된 요소 때문에 나타날 수 있음.
4) analyze performance metrics
SRM을 가지는 scorecard에서 로딩 시간이나 충돌과 같은 주된 성능 지표에 큰 저하가 있다면, SRM의 원인이 될 수 있음.
ex. treatment는 페이지 로드 시간이 증가하면 저하된 PLE를 가지는 몇 유저로부터 telemetry를 받지 않을지도 모름. 그러나 telemetry을 가진 사용자에 대한 control과 treatment를 비교할 때도 여전히 regression이 나타남.
5) analyze engagement metrics
유저당 평균 참여도가 control가 비교했을 때 treatment에 높게 나타나면 SRM의 근본 원인은 참여도가 낮은 유저가 더 영향을 주고, 반대도 그러함.
ex. Skype SRM의 경우, 근본 원인은 참여 기간이 긴 세션에 영향을 주는 시스템 버그 때문이었음.
6) count frequency of SRMs
서로 다른 많은 실험에 SRM를 가진다면 SRM의 근본 원인은 광범위한 영향을 미치는 분류 체계로부터의 하나 또는 이상의 요소로 인한 시스템 문제 때문일 것임.
7) Examine AA experiment
A/A 실험이 SRM를 가진다면 광범위한 요소 중 하나가 SRM의 근본 원인이거나 실험이 사실 A/A가 아님.
ex. 변형 중 하나에 추가의 telemetry를 추가하면 변형이 더 많은 유저를 복구할 수 있어 A/A가 아님.
8) Examine severity
매우 크거나 작은 샘플 비를 관찰했다면 근본 원인은 control, treatment에 각각 많은 유저에 영향을 줄 것임.
ex. 한 변형에 유저가 없다면, control 변형 또는 control의 트리거 조건이 제대로 기록되지 않는 telemetry 문제일 가능성이 있음.
9) Examine downstream
파이프라인에서 여러 수집 및 aggregation 단계에 데이터를 검사할 수 있는 경우, 여러 단계에서 결과를 비교하면 SRM이 생기는 곳의 단서를 줄 수 있을 것임.
10) Examine across pipelines
실험 시스템이 두 데이터 파이프라인을 가진다면, 두 파이프라인의 결과를 비교해라. 또한, 파이프라인에 결합될 수 없는 기록을 포함하는 디버깅 로그를 검사해라.



