"Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation" - Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio (2014)

Abstract
RNN encoder-decoder로 불리는 모델을 제안함. 이는 두 개의 RNN으로 구성된 것으로 한 RNN은 가변적인 시퀀스를 고정된 길이의 벡터 표현으로 인코딩하고, 다른 RNN은 그 표현을 다른 시퀀스로 디코딩함. 이 모델은 jointly conditional probability를 최대화하는 방향으로 학습함. SMT 성능도 향상되었고, 질적으로도 문맥, 문법측면에서 의미있는 표현을 학습함.
Introduction
최근의 연구에서 neural network는 여러 NLP task에서 성공적으로 사용되고 있음. SMT 분야에서도 deep neural network가 유망한 결과를 보여주고 있음.
SMT에서 nerual network를 활용한 연구를 진행함에 따라 본 논문에서는 RNN을 활용한 새로운 neural network 구조에 초점을 맞춤.
RNN Encoder-Decoder
- RNN (Recurrent Neural Network)
hidden state h, optional output y
variable-length sequence x = (x_1, … , x_T)
이전 hidden state 값과 현재 x_t값을 사용해 현재 hidden state 값을 예측함.
f : non-linear activation function (logstic sigmmoid function)
각 단계마다 새로운 시퀀스로 output은 conditional dstn으로 계산함.
- RNN Encoder-Decoder
확률론적인 관점에서 새로운 모델은 가변적인 시퀀스로부터 또 다른 가변적인 시퀀스의 conditional dstn를 학습하는 방식임.
- encoder
RNN은 input sequence의 각 symbol을 읽고, hidden state에서 값을 계산함. 가변적인 길이의 시퀀스를 고정된 길이의 벡터 표현으로 인코딩해줌. 시퀀스의 끝을 읽은 후에는 hidden state는 전체 Input의 요약체인 c를 계산함.
- decoder
hidden state가 주어졌을 때 다음 symbol y_t를 예측함으로써 output sequence를 만들어냄. 인코딩된 벡터를 통해 다른 시퀀스를 디코딩함.
다음 symbol의 conditional dstn을 학습해 y_t를 예측함.
- training
두 RNN은 jointly하게 conditional log-likelihood를 최대화하는 방향으로 학습함.
theta : 모델의 파라미터셋
gradient-based 알고리즘으로 모델의 파라미터를 추정함.
input sequence가 주어졌을 때의 target sequence를 만들어낼 수 있음.
모델은 input, output 쌍이 주어져 score를 계산할 수 있음. (conditional probability)
- Hidden Uint that adaptively remembers and forgets
- 1) reset gate
W_r, U_r : weight matrices
- 2) update gate
W_z, U_z : weight matrices
reset gate가 0에 가까워질 때 이전 hidden state를 무시하고, 현재 input으로 reset하도록 만듦.
update gate는 얼마나 이전 hidden state의 정보를 현재에 가져올지를 통제함.
두 gate를 통해 시간에 따른 의존도를 포착해 훈련할 수 있음.
- SMT (Statistical Machine Translation)
시스템의 목표 : source sentence e가 주어졌을 때, 통계적 모델을 활용해 번역 f를 찾는 것

f_n : n-th feature, w_n : weight, Z(e) : 가중치에 영향 받지 않는 normalized constant
가중치는 BLEU score를 최대화하는 방향으로 최적화됨.
논문에서는 SMT 중 pharse-based 방법을 사용하고 source와 target에서 매칭하는 phrase들의 확률로 분해해서 구함. 각 phrase table에서 phrase pair를 점수 매겨 이 pair의 연결성, 패턴을 학습하는 방법으로 연구 초기에는 word-based 였지만 이는 정확도가 떨어져 현재는 phrase-based를 많이 사용함.
Experiments
- BELU

i-gram의 precision의 기하평균을 곱해줌.

RNN은 baseline보다 좋은 성능을 보였고, CSLM과 결합한 방식이 더 성능이 좋음을 확인할 수 있음.
WP : Word Penalty

source가 주어졌을 때 높은 score를 가지는 target들을 나열한 것으로, 짧은 문장에서 일반적으로 성능이 좋음을 확인할 수 있음.
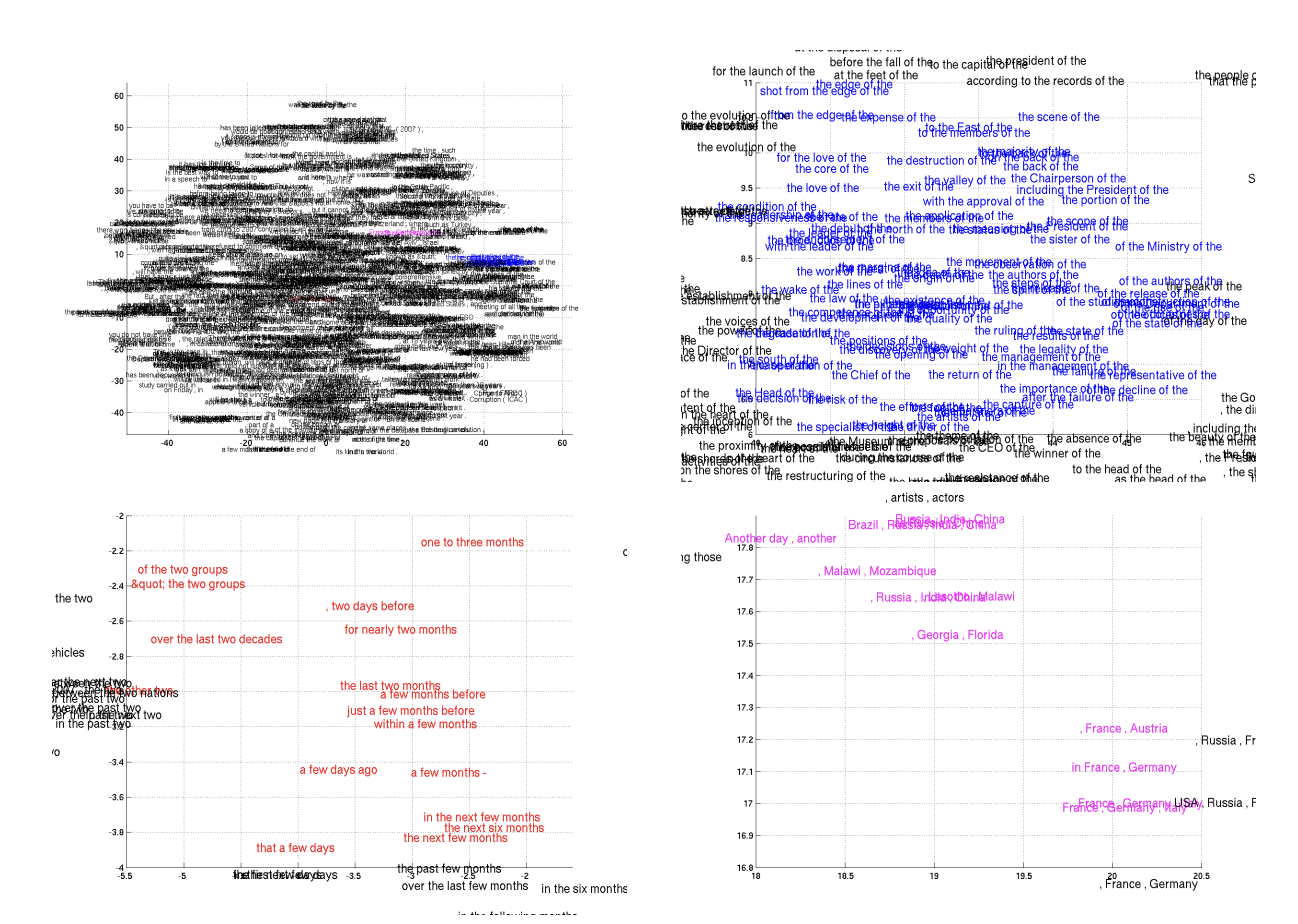
번역한 문장을 2D embedding으로 시각화함. 유사한 문장 구조를 가지거나 비슷한 의미를 가진 문장까지 모여있는 형태를 띔.



