
"FastText : Enriching Word Vectors with Subword Information" - Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov (2016)
Abstract
기존 skip-gram 단어 표현에 character n-gram 정보를 추가한 subword model을 제시함.
Introduction
word vectors representation을 학습시키는 방법론을 다룸.
word2Vec는 한 단어에 대해 고유한 벡터를 할당 하기 때문에 단어의 형태학적인 특징을 반영할 수 없음. 비슷한 의미를 가지는 두 단어가 서로 다른 벡터를 할당받게 됨을 의미함. 이렇게 같은 의미를 가진 단어들이 서로 다른 벡터를 할당하게 되면, 단어의 수가 늘어나면 학습 속도가 급격히 저하됨. → 이를 해결하기 위해 skip-gram을 기반으로 한 n-gram 벡터의 조합으로 표현하였으나 이도 형태학적으로 복잡한 언어는 잘 표현하지 못함.
Model
Word2Vec (Continuous Skip-gram)
word2vec모델의 학습방법은 총 w개의 단어가 있을때 각 단어들의 단어들에 대해 백터를 할당해주고 주변에 있는 단어들에 대해 어떠한 단어들이 올지 잘 예측할수 있게 학습 진행함.

t개의 라는 주변의 문맥 단어가 주어졌을 때 w_c를 잘 맞추는 방향으로 학습을 진행함. 즉, 어떤 주변 문맥 단어가 주어졌을 때 확률 값이 높은지를 파악해 이를 최적화하는 방향으로 학습함.

각 확률값은 softmax의 함수 식을 따름. 그러나 word2vec은 해당 식을 사용하지 않음. 이는 주변의 문맥 단어 중 한 개에 대해서는 잘 맞출 수 있으나 다른 단어에 대해서는 예측이 어려울 수 있음. (하나를 잘 맞추는 방향으로 학습하면 나머지 단어를 예측하기 어려움.)

따라서 word2vec은 negative sampling 방식을 사용함. 이는 학습 시 전체 단어 집합이 아니라 일부 단어 집합에만 집중하도록 하는 방법을 의미함.
Subword Model

가장 앞과 뒤에 <, >을 더해 prefix와 suffix를 구분함. n-gram으로 나눌수 있는 모든 경우의 수들의 단어 벡터를 더한 값을 하나의 벡터로 subword model임.

g : n-gram의 dictionary size
G_w : 단어 w에서 나올 수 있는 모든 n-gram의 경우의 집합
z : 하나의 n-gram vector representation

Orange라는 단어를 2~5 gram으로 나타낸 값과 original 값을 더한 값을 하나의 벡터로 사용함.
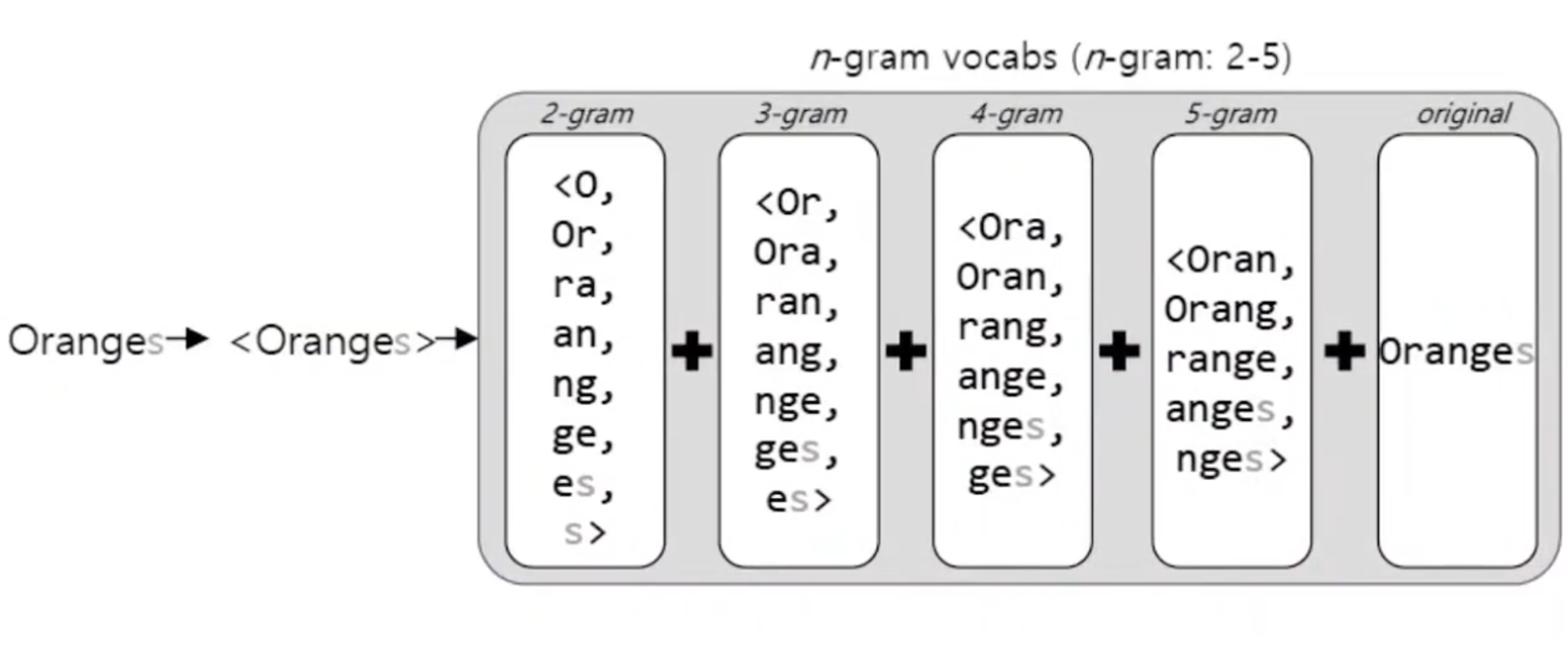
Subword model은 모르는 단어(Out Of Vocabulary, OOV, 사전에 없는 단어)에 대해 위와 같이 n-gram을 사용해 다른 단어와의 유사도를 계산할 수 있음. → 원래 단어에서 파생된 단어들의 표현을 서로 공유할 수 있음.
Experiment


- sisg : FastText 모델
- sigs- : OOV문제를 해결하지 않은 FastText 모델
- cbow : Word2Vec의 CBOW 모델
ssig가 가장 좋은 성능을 보이며, semantic 부분에서 더 큰 성능 개선을 보임.

데이터 수가 적을 때 다른 모델보다 더 높은 성능을 보여줌.
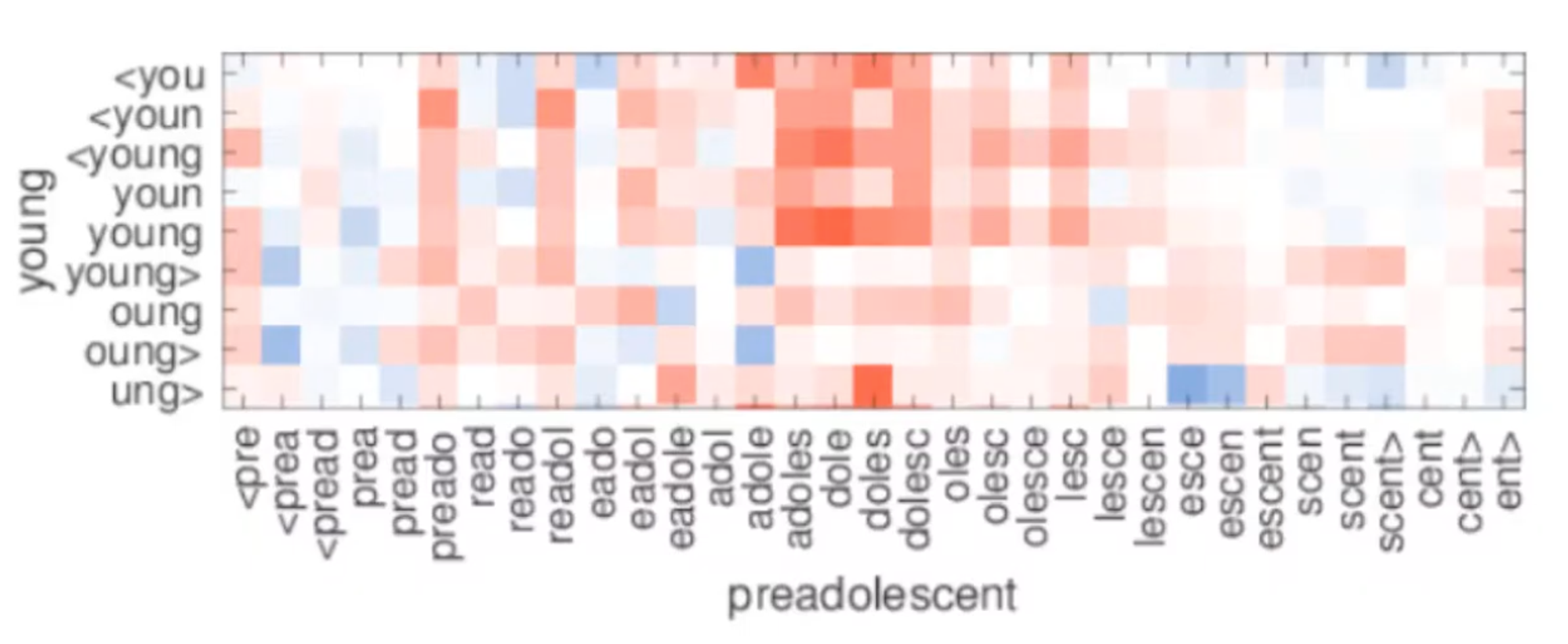
x축 : OOV, y축 : 학습 데이터 셋 내 단어
preadolescent를 학습할때 유사도가 높은 young을 일부 반영(young, dole, doles)하여 학습이 진행됨.



