"Recurrent neural network based language model" - Toma´s Mikolov, Martin Karafiat, Luka´s Burget, Jan “Honza” Cernocky, Sanjeev Khudanpur (2010)

Introduction
Sequential data prediction은 머신러닝과 인공지능 분야에서 해결해야 하는 문제 중 하나로, 이 중에 parsing tree를 이용하거나 단어의 형태를 분석하는 방법의 통계적 언어 모델으로 주어진 context를 기반으로 다음 단어를 예측함.
기존의 n-gram 기반의 언어 모델에서 발전한 RNN 모델을 제시함.
Model
input layer x, hidden layer, output layer y로 구성됨.
x(t)는 time t의 입력, y(t)는 time t의 결과, s(t)는 state가 됨.
RNN은 동일한 태스크를 한 시퀀스의 모든 요소마다 적용하고 출력 결과는 이전 계산 결과에 영향을 받음.
RNN 계층은 그 계층으로의 입력과 직전의 RNN 계층으로부터의 출력을 입력으로 받아 현 시각의 출력을 계산함.
- : 시간 스텝에서의 입력 벡터, one-hot vector 형태
- : 입력 벡터 에 대한 word embedding
- : 시간 스텝에서 RNN의 기억을 담당하는 hidden state
- RNN에는 가중치가 2개 있음.
- : 입력 의 임베딩 를 출력 로 변환하기 위한 가중치
- : RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치
- b : bias
Training
- 단어 들로 이루어진 시퀀스의 큰 corpus를 준비함.
- 를 순서대로 RNN-LM에 입력하고, 매 step 에 대한 출력분포 를 계산함.
- 주어진 단어에서부터 시작하여 그 다음 모든 단어들에 대한 확률을 예측
- step 에 대한 손실함수 Cross-Entropy를 계산함.
4. 전체 training set에 대한 손실을 구하기 위해 평균값을 구함.
Experiment
성능 개선을 위해 train text 중 threshold 이하의 빈도를 나타내는 단어는 special rare token으로 합쳤고, 단어 확률은 다음과 같이 계산됨.
C_rare : threshold 이하의 빈도를 나타내는 단어의 수
모든 rare 단어들은 distributed uniformly probability를 가짐.
BLAS 라이브러리를 사용해 다른 연구에 비해 매우 빠른 6시간 만에 학습을 함.
WSJ experiments
DARPA WSJ’92와 WSJ’93 데이터셋에서 100개의 best list를 추출함.
Oracle WER는 dev set 6.1%, eval set 9.5%를 사용함.
training corpus는 English Gigaword의 NYT 섹션의 37M 단어로 구성했고, RNN LM을 학습하기에 시간이 오래 걸려 본 연구에서는 최대 6.4M 단어를 사용함. (300K 문장)
⭐ 들어가기 전
Perplexity : 텍스트 생성 언어 모델의 성능 평가지표의 한 종류로 얼마나 확률 분포가 데이터를 잘 설명하는지 설명하는 값으로 문장 확률을 문장의 길이로 정규화된 역수로 값을 계산한다. 이전 단어에서 다음 단어를 예측할 때 몇 개의 후보를 고려하는지를 의미하며, 후보가 많다는 것은 모델이 쉽게 정답을 찾아낼 수 없다는 것이므로 지표값이 낮을수록 정확도가 높음.
WER (Word Error Rate) : 음성 분석 모델의 성능 평가지표의 한 종류로, 인식 문장과 정답 문장 사이의 단어 오류 비율을 나타내는 지표, 지표값이 낮을수록 정확도가 높음.
- S_w : 대체 오류, 철자가 틀린 음절 횟수
- D_w : 삭제 오류, 음절의 누락 횟수
- I_w : 삽입 오류, 잘못된 음절의 포함된 횟수
- N_w : 참조의(Ground truth) 음절 수
- CER (Character Error Rate) : 음성 분석 모델의 성능 평가지표의 한 종류로, 인식 문장과 정답 문장 사이의 음절 오류 비율을 나타내는 지표, 지표값이 낮을수록 정확도가 높음.
- S : 대체 오류, 철자가 틀린 단어 횟수
- D : 삭제 오류, 단어의 누락 횟수
- I : 삽입 오류, 잘못된 단어가 포함된 횟수
- N : 참조의(Ground truth) 단어 수
평가지표인 Perplexity는 held-out 데이터에서 평가됨.
결합 모델은 RNN LM을 0.75로 backoff LM을 0.25로 가중치를 둔 선형 보간법임.
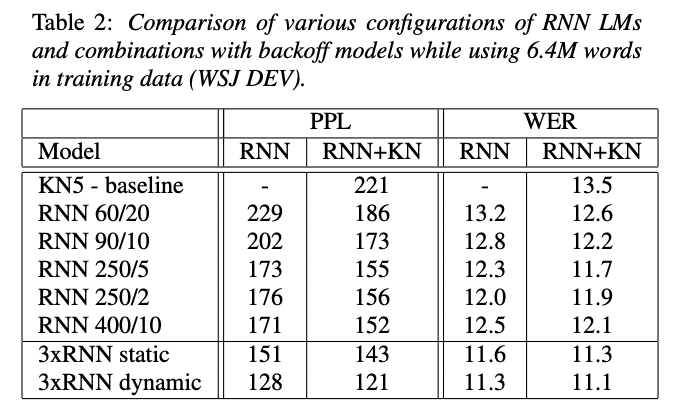
RNN 90/2 같은 신경망의 구성은 hidden layer size가 90이고, rare token을 단어로 합치는 threshold가 2임을 나타냄.
⇒ 더 많은 데이터를 사용할수록 성능이 증가함을 시사함.
⇒ Kneser-Ney smoothing 5-gram (KN5)와 dynamic 3*RNN LM 혼합 모델을 비교하면 WER의 감소는 약 18%임.
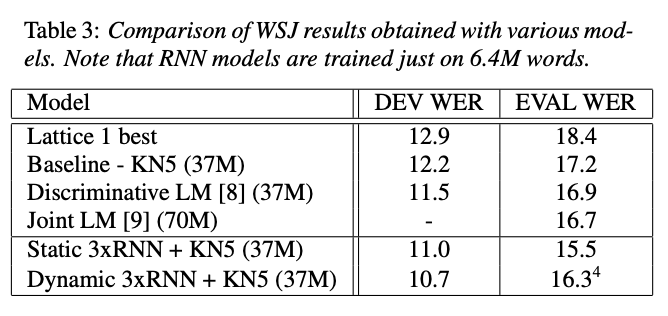
⇒ 37M 단어 기반 backoff 모델을 사용한 결과이며, RNN 기반 모델은 backoff 모델에 비해 WER을 약 12% 줄일 수 있었음.
NIST RT05 experiments
이전 실험의 경우 baseline 대비 개선을 보여주었지만, 이런 모델들은 SOTA와 거리가 멀고 잘 조정된 시스템을 개선하는 것보다 쉬운 태스크에 속할 것임. 사용된 단어 수 역시 작업에 적용하기 위한 수보다 훨씬 적기 때문에 NIST RT05 평가에 사용되는 AMI 시스템에서 생성된 lattices로 실험함.
feature extraction은 HLDA에 의해 39차원 특징 벡터로 감소된 델타, 이중 델타, 삼중 델타가 포함된 13개의 Mel-PLP feature를 사용함.
AMI 시스템에서는 4 gram LM을 사용했고 다양한 데이터에 의해 훈련됨. 훈련 데이터의 양은 1.3G 단어 이상이었고, RT05 LM로 표기된다. 이 성능을 비교한 표가 위의 표4임.
RT09 LM은 추가 CHIL 및 웹 데이터에 의해 확장됨. RNN LM을 훈련하기 위해서는 5.4M 단어에 대해 제한된 도메인 데이터를 선정했고, RNN LM의 훈련 데이터는 RT05와 RT09를 구성하는 데 사용한 데이터의 부분 집합이라는 것을 의미함.
⇒ 많은 데이터를 사용한 모델에 대해서도 WER 값을 낮추었고, RNN 계열이 성능이 좋음을 확인함.
Conclusion
RNN 모델이 backoff 모델의 성능을 뛰어넘었음을 증명함.
기존의 n-gram을 통해 만들어진 언어 모델링보다 순환 신경망 학습과 같은 온라인 학습이 중요한 효과가 있음을 확인함.
또한, task 또는 언어 고유의 가정을 하지 않았기에 기계 번역이나 OCR과 같이 backoff 모델을 사용하는 여러 종류의 응용 프로그램에서 RNN 모델을 쉽게 사용할 수 있음.
'논문 리뷰' 카테고리의 다른 글
| [ELECTRA : Pre-training Text Encoders as Discriminators Rather Than Generators] (0) | 2024.03.10 |
|---|---|
| [ELMo : Deep contextualized word representations] (2) | 2024.03.06 |
| [Deep Neural Networks for YouTube Recommendations] (1) | 2023.08.06 |
| [BPR: Bayesian Personalized Ranking from Implicit Feedback] (0) | 2023.07.30 |
| [One-Class Collaborative Filtering] (0) | 2023.07.23 |



