" Improving Language Understanding by Generative Pre-Training " - Alec Radford, Karthik Naraismhan, Tim Salimans, Ilya Suskever (2018)

본 논문에서는 …
generative pre-training과 discriminative fine-tuning을 통해 task에 대한 지식이 없이 언어를 이해하는 framework를 제시함.
- unlabeled data가 langauge modeling objective를 사용하여 초기 파라미터들을 학습함.
- labeled data를 사용하여 이 초기 파라미터들을 주어진 목표 작업에 맞게 조금씩 수정함.
→ unlabeled data와 labeled data가 같은 영역에 속할 필요가 없음.
연구 배경
Natural language understanding은 두 문장 간의 추론 문제, 두 문장의 의미적 동일성, QA 문서 분류와 같은 다양한 task로 구성됨. 그러나 unlabeled text는 많지만, labeled text는 적어 모델 훈련에 어려움이 있음.
unlabeled text를 효과적으로 학습하는 것은 지도학습에 의존하는 방식을 완화하고 많은 시간과 비용을 들이는 annotation 작업을 대체할 수 있는 등 여러 이점이 있어 중요함.
unlabeled text를 학습하는 것에 대한 어려움
- transfer에 유용한 text 표현을 배우는 것에 어떤 형태의 optimization objective가 가장 좋은지 불분명함. → task 마다 다른 objective가 성능이 좋음.
- 학습된 표현들을 target task로 transfer 시키는 가장 효과적인 방법이 불분명함. → 현재는 복잡한 학습 방법과 보조 learning objective를 결합하여 사용하는 기술이 있음.
이들은 semi-supervised learning을 더 어렵게 만듦.
관련된 연구
- Semi-supervised learning for NLP
초기 연구는 unlabeled data를 사용해 단어 수준 혹은 문맥 수준에서 계산하여 이를 supervised model의 feature로 사용했음. 지난 몇 년 동안은 연구자들이 단어 embedding을 사용한 헤택을 발견함.
→ 이런 접근은 주로 단어 수준의 정보를 transfer한다는 점에서 한계가 존재함. 최근에는 문맥 수준 혹은 문장 수준의 embedding을 시도함.
- Unsupervised pre-training
지도 학습 objective를 수정하는 것이 아니라 좋은 시작점을 찾는 것이 목표임.
비슷한 연구에서 language modeling objective를 사용해 pre-training하고 target task에 대해 fine-tuning을 진행했음. 그 연구에서는 pre-training을 할 때 LSTM을 사용했는데 짧은 범위에 대해서만 모델이 예측을 했고, pre-trained language 또는 기계 번역 모델에서 가져온 은닉 표현을 보조 feature로 사용하는데 이는 독립된 target task에 대해 많은 양의 새로운 파라미터를 요구함. 하지만 본 연구의 transformer는 긴 범위의 데이터에서도 유효하며, transfer 시 모델에 최소한의 변화만 요구함.
- auxiliary training objectives
이를 추가하는 것은 semi-supervised learning의 대안에 가까움.
POS tagging, chunking, named entity recognition과 같은 보조 NLP 작업을 사용해 sementic role labeling을 개선하였으며, 최근에는 이를 target task objective로 사용해 성능을 개선함.
본 논문에서도 이를 사용하지만, 비지도 pre-training이 이미 target task와 관련된 언어적 정보들을 학습함.
Model
훈련은 두 단계로 구성됨.
- 많은 양의 데이터를 가진 언어 모델을 학습함.
- labeled data에 대해 다른 task를 하도록 fine-tuning을 진행함.
- Unsupervised pre-training
unsupervised corpus가 주어졌을 때 likelihood를 최대화하는 방향으로 언어 모델이 학습됨. 파라미터는 SGD로 학습됨.

본 논문에서는 multi-layer Transformer decoder를 언어 모델로 사용함. multi-headed self-attention을 input에 적용하고, position-wise feedforward layer를 거쳐 출력 분포를 만들어냄.

- Supervised fune-tuning
target task에 맞게 파라미터를 조정함.

y를 예측하기 위해 pre-trained model에서 얻어진 h^m_l과 W_y가 linear output layer에 추가됨.

이 likelihood를 최대화함.

언어 모델에 auxiliary objective를 fine-tuning에 포함시키는 것이 일반화를 향상하고 수렴을 가속화하는 것을 도와 위와 같은 auxiliary objective를 최적화함.

- Task-specific input transformations
텍스트 분류는 바로 fine-tunining이 가능하지만, 다른 작업은 구조화된 input이 필요해 약간의 수정이 필요함. 이전 연구에서는 transfer된 표현 위에 새롭게 task에 맞는 구조를 쌓아 모델을 만듦. 본 논문은 대신 traversal-style 접근법을 사용해 target task에 맞는 구조화된 input을 사전학습 모델이 사용할 수 있는 ordered sequence로 변환함.
실험 환경
- Unspervised pre-training
BookCorpus 데이터셋을 사용함. 길고 연속적인 text를 포함해 긴 범위의 정보를 학습 가능함.
- Model
주로 본래의 Transformer를 따름. 12개 층의 maksed self-attention head를 가지는 decoder only transformer, Adam optimizer, learning rate는 2,000 step까지는 최대 2.5e-4까지 선형적으로 증가하다 cosine schedule에 따라 0으로 서서히 감소함. GELU activation function을 사용함.
- fine-tuning details
unsupervised pre-training hyperparameter와 세팅이 거의 동일하며 dropout을 추가하고, 6.25e-5의 learning rate, 32 batch size를 사용함.
결론
supervised fune-tuning
- Natural Language inference
문장의 쌍이 함의, 모순, 중립 중 어떤 것인지 판단하는 문제임. SNLI, MNLI, QNLI, SciTail, RTE 데이터셋을 다룸. 큰 NLI 데이터셋에 높은 성능을 고려하면 multi-task training에 이점이 있을 것임.

- Question answering and commonsense reasoning
QA 문제임. 중, 고등학교 시험 문제로 이루어진 RACE 데이터셋, 두 옵션으로부터 올바른 엔딩을 선택하는 문제를 다룬 Story Cloze Test 데이터셋을 사용함. 성능 향상을 보였으며, 이는 긴 범위의 문맥도 효율적으로 다룰 수 있음을 의미함.

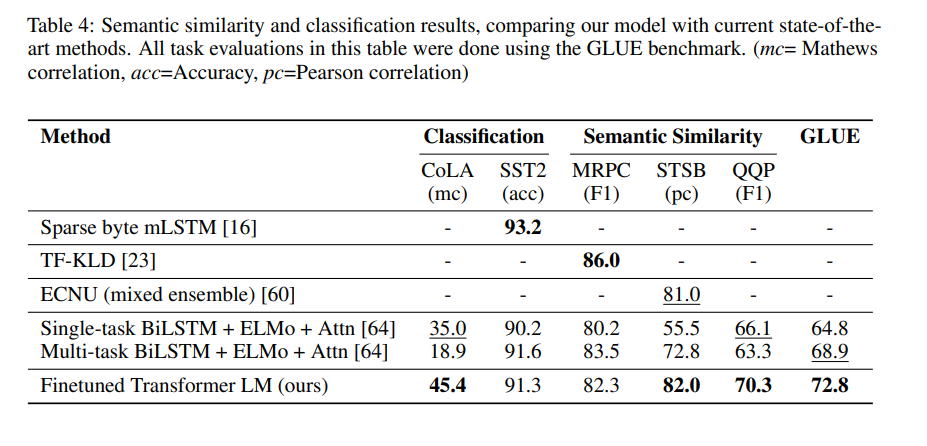
- Semantic Similarity
두 문장이 의미적으로 같은지 다른지를 판단하는 문제임. MRPC, QQP, STS-B 데이터셋을 다룸.
- Classfication
두 개의 text classification task를 평가함. 문법적으로 맞는지를 판단하는 CoLA와 단순한 이진 분류로 사용되는 SST-2 데이터셋을 다룸.
- Impact of number of layers transferred
pre-training과 fine-tuning에 사용되는 transferred 층의 개수의 영향을 관찰함.
pre-trained model에 유용한 기능을 포함한다는 것을 의미함.
- Zero-shot Behaviors
왜 transformer를 사용한 pre-training이 효과적인지 관찰함.
pre-training을 통한 fine-tuning 없이 generative model 그 자체로 작업을 수행함.
학습 횟수에 따라 안정적으로 성능이 증가하는 것으로 보아 generative pre-training이 광범위한 종류의 작업을 배우는 것에 도움을 줌.
LSTM이 높은 분산을 보여주는데 transformer 구조의 귀납적인 편향이 transfer를 돕는 것을 의미함.

- Ablation studies
- fine-tuning할 때 auxiliary LM objective 없이 성능을 관찰함. → 이가 NLI task와 QQP에 도움을 주는 것을 확인함. 전반적으로 큰 데이터셋은 auxiliary objective의 도움을 받지만 작은 데이터셋은 도움을 받지 않음.
- 같은 framework를 사용하면서 2048 unit LSTM와 Transformer를 비교함. → LSTM을 사용할 때 평균적으로 5.6 score가 떨어짐.
- pre-training을 거치지 않고 바로 target task에 맞게 훈련한 transformer 구조를 확인함. → 이를 거치지 않는 것이 모든 작업에서 성능이 저하됨을 확인함.
'논문 리뷰' 카테고리의 다른 글
| [XLNet : Generalized Autoregressive Pretraining for Language Understanding] (0) | 2023.03.25 |
|---|---|
| [BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding] (0) | 2023.03.25 |
| [Attention Is All You Need] (0) | 2023.03.20 |
| [Sequence to Sequence Learning with Neural Network] (0) | 2023.03.15 |
| [Efficient Estimation of Word Representation in Vector Space] (1) | 2023.03.15 |



