" Attention Is All You Need " - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin (2017)

본 논문에서는 …
RNN or CNN을 사용하지 않고 attention에 기반한 sequence transduction model인 Transformer를 제안함. 이는 더 많은 parallelization을 가능케하여 더 높은 성능을 보여줌.
연구 배경
RNN, LSTM, gate RNN은 대표적인 sequence transduction model로 알려져 있음. Recurrent Model은 일반적으로 input과 output sequence의 symbol position에 따라 계산함. 계산 단계에 따라 hidden state인 h_t, 이전의 hidden state인 h_(t-1)그리고 input의 위치인 t가 생성되며, 이는 parallelization을 막음. 최근 연구는 이를 factorization tricks이나 conditional computation으로 성능을 개선하였지만, 근본적인 제약은 여전히 존재함.
sequential 연산을 줄이기 위한 많은 노력이 있었지만 이는 모두 CNN을 사용하며, 떨어져 있는 단어 사이의 dependency를 학습하는 데 어려움이 있음.
또한, attention mechanisms은 input과 output의 거리에 상관없이 의존성을 모델링하여 여러 sequence transduction model에 필수적인 부분이 되었지만, RNN 네트워크의 결합과 함께 사용된 한계가 있음.
end-to-end 메모리 네트워크는 sequence-aligned recurrence 대신 recurrent attention mechanism을 기반으로 하며, 다양한 분야에서 성공적으로 사용됨.
Model
많은 sequence transduction model은 encoder-decoder 구조를 가짐. 이런 모델의 각 단계에서는 auto-regressive며, 다음을 생성할 때 이전의 input으로 생성된 output을 사용함.
transformer는 stacked self-attention과 fully connected layers를 사용한 구조를 따름.

- encoder
인코더는 N=6개의 동일한 층의 stack으로 구성됨. 각 층은 두 개의 서브 층으로 구성되는데 첫 번째는 multi-head self-attention mechanism, 두 번째는 fully connected feed-forward network임. 각 서브층은 residual connection과 layer normalization을 사용함. 즉, 각 서브 층의 output은 LayerNorm(x + Sublayer(x))임. residual connection을 용이하게 하기 위해 모델의 모든 서브 층은 512차원의 output을 생성함.
- decoder
디코더도 N=6개의 동일한 층의 stack으로 구성됨. 각 인코더 층의 두 개의 서브 층뿐 아니라 디코더는 multi-head attention을 수행하는 세 번째 서브 층을 추가함. 나머지 환경은 인코더와 비슷하나 self-attention 서브 층의 수정이 있음. 위치가 subsequent 위치들에 관여하는 것을 막음. output embedding이 한 위치의 offset이라는 사실과 결합한 masking은 위치 i에 대한 예측이 i보다 적은 값의 위치로 알려진 output에만 의존할 수 있도록 함.
- attention
attention function은 query, keys, values, output이 모두 벡터인 output에 매핑하여 나타냄. output은 values의 weighed sum에 의해 계산되며, key에 대응하는 query의 compatibility function에 의해 각 weight들이 계산됨.
- Scaled Dot-Product Attention
input은 d_k 차원의 query와 key, d_v 차원의 value로 구성됨. key와 query의 dot product를 계산하고 루트 d_k로 나누어 softmax를 적용해 value에 대한 weight를 구함.
주로 사용되는 attention function은 additive attention과 dot-product attention이 있음.
- dot-product attention : 루트 d_k를 나누는 것 제외하면 위와 동일함.
- additive attention : single hidden layer가 있는 feed-forward network를 사용해 compatibility function을 계산함.
→ dot-product attention이 최적의 matrix 계산을 통해 구현됨으로 더 빠르고 공간이 효율적임.

- Multi-Head Attention
d_model 차원의 keys, values, queries를 사용해 single attention을 수행하는 대신, d_k, d_k, d_v 차원에 대해 각각 선형 projection을 사용해 h번 선형 projection을 수행하는 것이 더 효율적이라는 것을 발견함. 각 projected 버전에 대해 병렬로 attention function을 수행하고(h번에 대해 Q, K, V의 값은 다 다름), d_v 차원의 output value를 생성해 다시 합쳐 projected하여 output을 생성함.
h=8개의 병렬 attention head를 사용하며, d_k, d_v, d_model/h = 64를 사용함. 각 head의 축소된 차원으로 전체 차원을 가지는 single-head attention과 전체 계산 비용은 동일함.
Query : 디코더의 이전 층 hidden state
Key : 인코더의 output state
Value : 인코더의 output state, 가중치가 곱해질 token

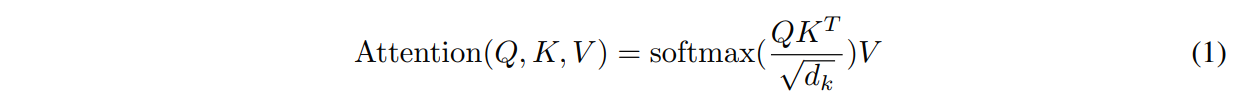
- applications of attention in our model
- “encoder-decoder attention” 층에서 query는 이전 디코더 층에서, key, value는 인코더의 output에서 얻음. 이를 통해 디코더의 모든 위치가 input sequence의 모든 위치에 배치될 수 있음.
- 인코더는 self-attention 층을 포함함. 인코더의 각 위치는 이전 층의 모든 위치에 관여할 수 있음.
- 디코더에 self-attention 층이 존재하며 디코더의 각 위치는 디코더의 모든 위치에 관여할 수 있도록 함. auto-regressive 특성을 보존하기 위해 leftward information flow를 막아야 함. 이를 위해 잘못된 연결에 해당하는 softmax의 input의 모든 value를 masking(-)으로 설정함으로써 scaled dot-product attention 안에서 이를 구현함.
- Position-wise Feed-Forward Networks
인코더와 디코더의 각 섭스 층에는 fully connecte feed-forward network가 있음. 이는 ReLU 함수의 두 개의 선형 결합으로 이루어져 있음. 선형 변환은 여러 위치에서 동일하게 이뤄지지만, 층마다 다른 파라미터를 사용함.
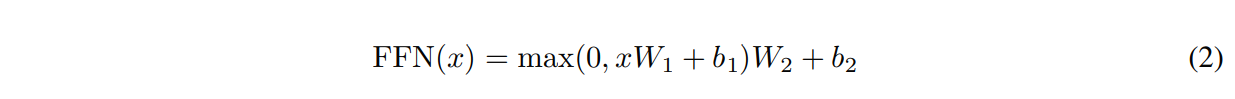
- Embeddings and softmax
다른 sequence transduction model과 비슷하게 학습된 embedding을 사용해 input과 output 토큰을 d_model 차원의 벡터로 변환함. softmax 함수를 사용해 다음 토큰의 확률로 변환함.
- Positional Encoding
위치 정보가 없어서 이에 대한 정보를 추가해야 함. 이를 위해 positional encoding을 인코더와 디코더 stack 아래 input embedding에 추가함. 이는 embedding과 동일한 차원으로 두 개를 합함.
본 연구에서는 sin, cos 함수를 사용함.

PE_pos+k가 PE_pos의 선형 함수로 표현되어 모델의 상대적인 위치를 쉽게 학습할 수 있으리라 생각해 삼각함수 사용함.
- self-attention 층과 recurrent, convolution 층과의 비교 수행
- 층 별 총 계산 복잡도
- 요구되는 최소한의 sequential 연산의 수로 측정된 병렬 연산량
- 장거리 의존성 사이의 path 길이
- → 장거리 의존성에 영향을 미치는 핵심 요소는 전달해야 하는 forward, backward signal의 길이, input과 output의 위치가 짧을수록 학습이 쉬움. 따라서 이의 maximum 길이를 비교함.

실험 환경
약 450만 개의 문장 쌍으로 구성된 WMT 2014 English-German 데이터셋에 대해 학습함. 8개의 NVIDA P100 GPU를 가진 하나의 기계에 대해 모델을 학습함.
β1 = 0.9, β2 = 0.98, ϵ = 10^-9인 Adam optimizer를 사용함, learning rate는 식에 따라 학습을 진행하며 변화시킴.
regularization을 위해 residual dropout과 label smoothing을 사용함. 서브 층의 input에 추가되고 normalization 되기 전에, 각 서브 층의 output에 대해 dropout(p=0.1)을 적용함. 인코더와 디코더의 모든 stack에 대해 embedding과 positional encoding의 합에 dropout을 적용함.
label smoothing의 경우 perplexity는 해치지만 BLEU score가 높아지는 결과를 보임.
결론
- Machine Translation

번역 task의 경우, Transformer는 RNN 혹은 CNN을 기반으로 하는 모델보다 훨씬 빠르게 학습이 됨.
- Model Variations

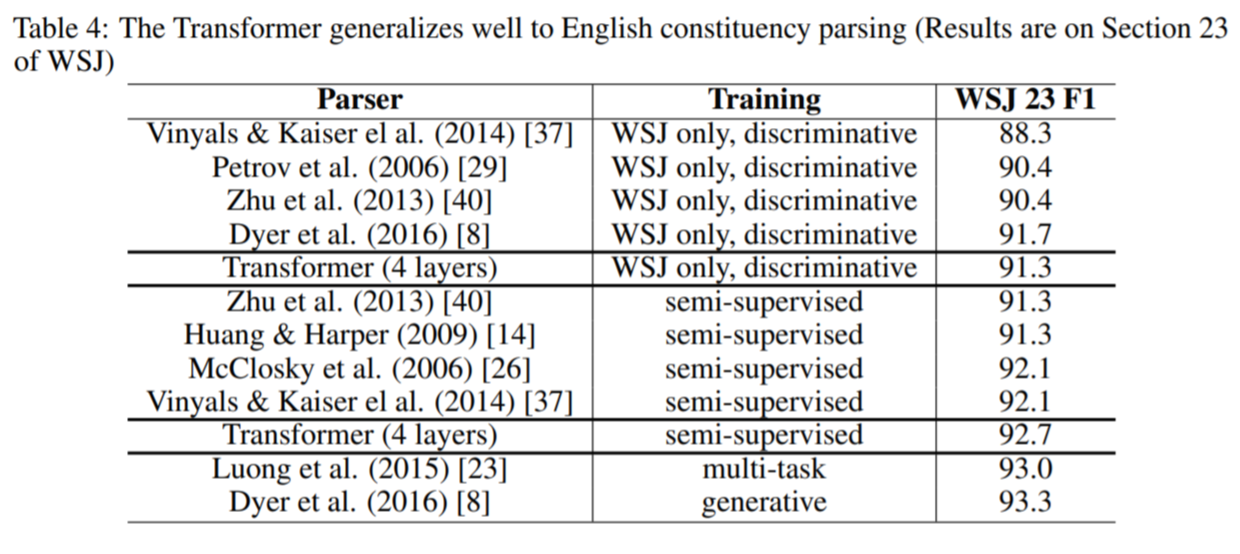
- English Constituency Parsing
이미지, 오디오, 비디오와 같은 큰 input과 output을 효율적으로 다루기 위해 Transformer를 확장할 수 있을 것임.



