CUAI 인공지능 학회 동계 컨퍼런스에 참여했다.

[1차 회의] - 주제 회의
데이콘 대회 나갈까, 노래 가사 감성 분석할까, 언어적 용인 가능성과 관련된 주제를 진행할까 ..
다양한 의견이 나왔다. 다들 조금 더 구체적으로 디벨롭해서 다음 회의 때 만나는 걸로 !
[2차 회의] - 주제 확정 및 기술 스케치
브로카 실어증 : 문장을 생략하고 문법에 맞지 않는 문장으로 의사소통을 하며, 간단하게 표현하는 증상을 보이는 실어증의 한 유형
브로카 환자가 발화하는 말을 듣고 완성된 문장을 제공해 환자가 올바른 문장 표현을 할 수 있도록 도와주는 서비스를 구현하자 !
어떤 모델을 사용할까?
문장에서 불완전한 부분에 Masked를 하고 이를 예측하는 MLM(Masked Language Model) 모델을 사용하자 !
ex) 환자의 발화 : 나 밥 먹다 -> 모델의 input : 나 <Masked> 밥 <Masked> 먹<Masked>
모델의 input은 텍스트 형식으로 제공되어야 할텐데 환자의 발화는 어떻게 텍스트로?
STT(Speech To Text) 기술을 이용하자 !
[3차 회의] - MLM 모델 및 STT 탐색
MLM 모델?
1) koELECTRA
2) MASS
3) KoBART
4) KoBERT
브로카 환자는 단어 뭉치만을 발화하므로 <Masked>의 경우는 문장의 조사나 어미에 붙이는 방향으로 가자.
STT 기술?
STT는 처음 공부해봤는데 이미 구글에서 SpeechRecognition이라는 모듈을 만들어두었고 무료로, 또 범용적으로 사용이 가능해 이 모듈을 사용하면 되겠다 판단했다.
[4차 회의] - 서비스 스케치
문장 완성에만 집중하기보다 더 넓게 나아가 낱말 이름 대기부터 실어증 환자의 실문법증 치료까지 단계적으로 수행이 가능한 서비스를 제안하는건 어떨까?
낱말 이름을 대는 가장 쉬운 단계와 사람의 행동을 체언과 용언을 결합해 간단한 문장으로 발화하는 그 다음 단계와 긴 문장을 완성해 발화하는 마지막 단계로 나누어 게임처럼 진행해보자 !
문장 완성의 경우, 대화형 치료 모델이 좋겠다. 환자에게 질문을 던지면 환자는 그에 맞게 발화를 하고 그 발화를 MLM 모델를 통해 완전한 문장으로 바꾸어준다.
환자에게 던지는 질문은 구현자인 우리가 리스트 형태로 여러 개 만드는 걸로.
[5차 회의] - 서비스 프로토타입 설정
단계별 3가지의 치료 방법을 크게 두 가지 기능으로 나누어보자 ! 정답이 있는 문제와 없는 문제.
정답이 있는 문제의 경우 또 두 가지로 나눈다. 하나는 사진을 보고 단어를 맞추는 단계, 또 하나는 사람의 행동과 관련된 사진을 보고 어떤 행동을 하는지 문장으로 표현하는 단계. STT 기술로 환자의 발화를 텍스트로 바꾼 후 정답인지 오답인지를 검증한다. 오답 시 힌트를 제공하도록 !
정답이 없는 문제는 4차 회의 때 논의했던 대화형 방식으로 환자에게 일상의 질문을 던지면 환자의 발화를 STT 기술로 텍스트로 바꾼 후 MLM 모델의 input으로 제공해 완전한 문장을 보여준다. 정답 문장 1개, 오답 문장 3개를 환자에게 보여주고 정답 문장을 고르도록 한다. 오답 시 정답을 확인하고 다음으로 넘어가도록 !
그렇게 총 3단계로 구성된 서비스를 제공하자 !
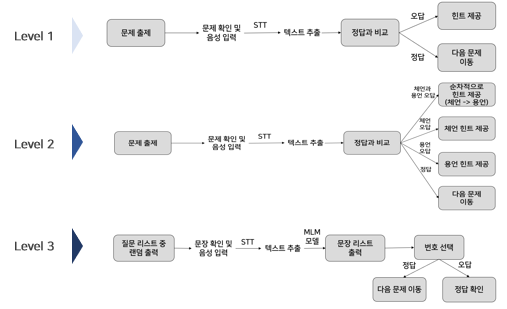
[6, 7차 회의] - 서비스 세부 기능 논의
위 흐름도처럼 정답이 있는 문제의 경우, 사용자가 오답을 발화하였다면 그 이후는 힌트를 제공한다.
1단계의 경우 단어의 초성과 동일한 랜덤 단어 리스트를 제공하거나 단어의 의미를 제공하는 방향으로,
2단계의 경우 문장 유사도를 계산하여 임계점보다 낮다면 의미와 관련된 힌트를, 임계점보다 높다면 시각적 힌트를 제공하도록 하자 !
KPMG에서 진행했던 역할 분담 방식 요긴하게 써먹었다.
좋은 건 바로 써먹어야지 ㅎ 최고 ,,
[8차 회의] - 모델 성능 높일 방안
모델은 maksed 예측이 잘 되는 KoBERT와 KoELECTRA 중 고민했다. 파라미터 개수와 perplexity 두 개를 동시에 고려해 최종으로 KoELECTRA를 선정하였다.
그렇다면 조금 더 나아가 우리의 모델이 목적에 맞게 찰떡인 output을 출력하기 위해 파인 튜닝을 진행해보면 어떨까?
데이터셋은 우리가,, 만들어 보쟈,, (1000개) 일상 대화 문장을 만들기 위해 열심히 머리를 쥐어짜내보았음.
ex) 요즘 더글로리라는 드라마가 재밌던데
[9차 회의] - 모델 성능을 높이기란 쉽지 않어
데이터셋이 작고 소중해서 성능이 생각보다 좋지 않았다. 그래서 KSS(Korean Single Speaker Speech) Data까지 사용했고, Hugging Face의 Electra Tokenizer를 사용해서 문장의 조사만 마스킹을 했다.
그래서 우리 모델은 마스킹된 조사를 예측하는 task에 대해 학습을 진행하였다.
[10차 회의] - 마무리 점검
최종 제출물인 ppt, short paper, 포스터 역할 분담하고 만들어서 피드백까지 깔끔하게 완료 !
마찬가지로 좋은 팀원들 만나서 으쌰으쌰 만들어갔다. 회의는 항상 웃다가 마무리 ,, 재밌는 사람덜
'활동' 카테고리의 다른 글
| [2023 KPMG 아이디어톤] (0) | 2023.03.15 |
|---|---|
| [2022 응통 분석 공모전] (0) | 2023.03.15 |

