" ResNet : Deep Residual Learning for Image Recognition " - Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun (2015)

본 연구에서는 …
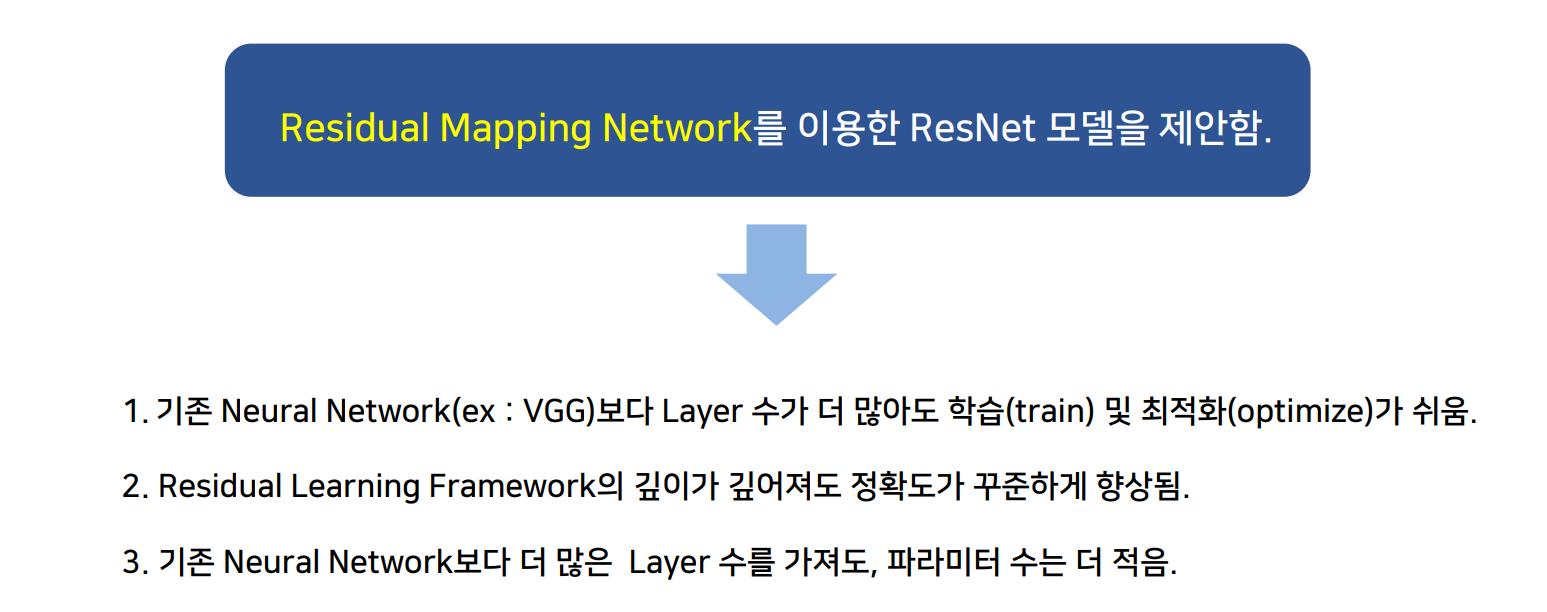
최적화하기 쉬우며 깊어진 nerual network의 학습을 용이하게 하기 위한 Residual Learning Framework를 적용한 ResNet 모델을 제안함.
연구 배경
각 feature들을 추출하기 위해 layer의 depth도 달라짐. 깊어질수록 vanishing / exploding gradient와 같은 문제가 생겨났고, 이를 normalized initialzation or intermediate normalization으로 해결함.
→ degradation 문제 발생 ( 성능 저하 문제 ), depth가 증가함에 따라 일정 수준에 도달하면 성능이 급격히 떨어지는 현상, overfitting으로 인한 것이 아님.
깊은 모델을 구성하는 해결책으로는 identity를 매핑하는 레이어를 추가하고 이외의 레이어는 학습된 shallow architecture를 복사하는 방법이 있음.
→ 이 방법이 좋은 성능을 내진 못함.
모델
아이디어
- Residual Representations
x → y로 mapping 할 때 residual vector를 인코딩하는 것이 original vector보다 효과적임.
- 핵심 1 : Residual Learning (식 변형)
F(x) = H(x) - x 입력과 출력의 차 최소화, H(x) = x, F(x) = 0으로 mapping이 목표 → H(x)보다 F(x)를 학습시키는 것이 더 쉬움.
H(x) = F(x) + x
멀티 그리드 방식 : 시스템을 여러 scale의 하위 문제로 재구성함.
- 계층 기반 pre-conditioning : 두 scale 간 residual 벡터를 가리키는 변수에 의존하는 방식
- 핵심 2 : Shortcut Connections
파라미터 추가 x, 0으로 수렴하지 않아 모든 정보가 통과됨.
모델의 구조
- plain network
- 동일한 output feature map size에 대해, layer는 동일한 수의 filter를 가짐.
- feature map size가 절반인 경우, layer 당의 time complexity를 보전하기 위해 filter의 수를 2배로 함.
downsampling 시에는 strides가 2인 conv layer를 사용했으며, 네트워크의 마지막에는 GAP(global average pooling layer)와 activation이 softmax인 1000-way FC layer로 구성됨. 이 plain network는 VGG-19에 비해 적은 수의 filter와 낮은 complexity가 가짐.
- residual network
shortcut connection 삽입 → F(x) + x 라는 식 생성됨.
input, output 차원이 다를 시,
- zero entry를 추가로 padding하여 dimension matching 후 identity mapping을 수행함. (별도의 parameter가 추가되지 않음)
- projection shortcut을 dimension matching에 사용함.
few stacked layers마다 residual learning을 사용함.
F = W2σ(W1x), F + x 연산은 shortcut connection 및 element-wise addition으로 수행되며, addition 후에는 second nonlinearity로 ReLU를 적용함.

F + x 연산은 둘의 dimension이 같아야 하며 output size가 달라졌다면, 이를 맞춰주기 위해 linear projection Ws을 수행함.
Ws는 dimension matching의 용도로만 사용함.
실험
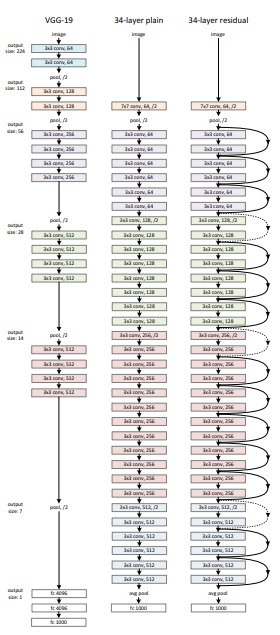
- Plain Networks
34 layer의 더 깊은 plain 모델에서 높은 Validation error가 나타남. → Vanishing gradient 때문에 발생하는 것은 아니라 판단함.
exponentially low convergence rate 때문에 성능 감소 추측함.
- Residual Networks
- degradation 문제가 잘 해결되었으며, depth가 증가하더라도 좋은 정확도를 얻을 수 있음을 의미함.
- residual learning이 extremely deep system에서 매우 효과적임.
- ResNet은 같은 상황에서 더 빨리 수렴함.
-> VGG 모델을 기반으로 만들었으며, VGG보다 층의 개수는 많으나 모델의 파라미터 수는 적음.
- Identity Shortcuts vs Projection Shortcuts

A. zero-padding shortcut는 dimension matching에 사용되며, 모든 shortcut는 parameter-free함.
B. projection shortcut는 dimension을 늘릴 때만 사용되며, 다른 shortcut은 모두 identity임.
C. 모든 shortcut은 projection임.
성능 : C > B > A

- Deeper Bottleneck Architectures
Layer가 깊어질수록 연산의 효율이 좋지 않아 1 x 1, 3 x 3, 1 x 1 conv로 구성하여 연산을 줄임.
이때 1 x 1은 dimension을 줄이거나 늘리는 데 사용되어(채널 수 조절, 연산량 감소, 복잡한 패턴을 더 잘 인식하도록 함.), 3 x 3 layer의 input / output 차원을 줄인 bottleneck 구조
만약 identity shortcut이 projection shortcut으로 대체되면, shortcut이 2개의 high-dimensional 출력과 연결되어 time complexity와 model size가 2배로 늘어남.

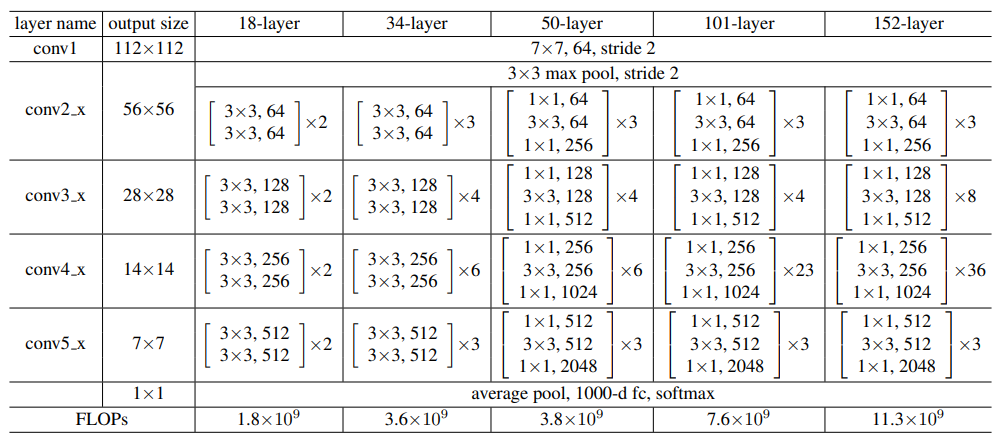
- Classification on ImageNet


ResNet의 경우 Degradation 문제를 해결함. 깊이를 증가해도 정확도가 향상됨을 확인함.
- CIFAR10 and Analysis
모델의 층 개수 : 6n + 2 에 n = 3, 5, 7, 9, 18 대입



ResNet의 경우 Degradation 문제를 해결함. 깊이를 증가해도 정확도가 향상됨을 확인함.
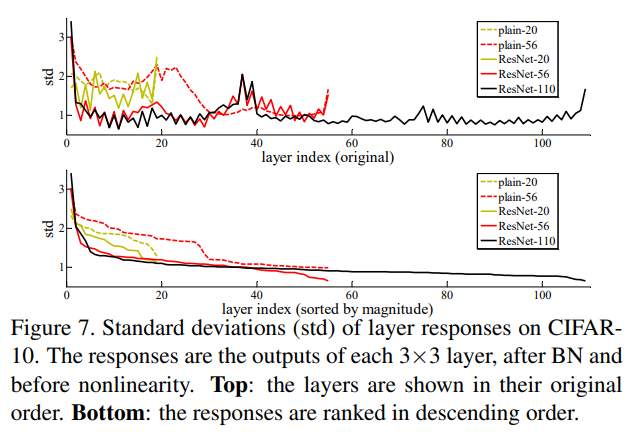
ResNet이 Plain Net보다 최적화가 용이하며 깊이가 깊어짐에 따라 성능이 향상됨을 확인함.

모델의 깊이를 매우 키운다면 overfitting이 발생함.
→ Dropout과 같은 규제로 해결이 가능함.
- Object Dectection on PASCAL and MS COCO

ResNet은 Task에 상관없이 범용적으로 성능이 좋은 모델임을 확인함.
결론