[Sequence to Sequence Learning with Neural Network]
" Sequence to Sequence Learning with Neural Network " - Ilya Sutskever, Oriol Vinyals, Quoc V. Le (2014)

본 논문에서는 ..
- sequence 구조 위에서 minimal assumption을 만드는 일반적인 end-to-end 방식의 학습 방법을 제시함.
- 단어의 순서를 거꾸로 하였을 때 LSTM의 성능이 향상되는 것을 찾아냄.
기계 번역이란 ?
인공 지능을 사용해 사람의 개입 없이 한 언어에서 다른 언어로 텍스트를 자동으로 번역하는 프로세스
(원본 텍스트의 소스 언어 의미 인코딩 → 의미를 타겟 언어로 디코딩)
Rule-based MT :
언어 전문가들이 특정 산업이나 주제에 맞는 내장된 언어 규칙과 사전을 개발하고 이를 참조해 소프트웨어가 번역하는 것
Statistical MT (SMT) :
특정 단어나 구가 타겟 언어에서 다른 단어나 구와 함께 있을 것이라는 통계적 확률에 기초하여 예측함.
Neural MT (NMT) : → 논문의 모델
인공지능을 사용해 언어를 배우고 신경망이라는 특정 기계 학습 방법을 사용해 지식을 지속적으로 개선함.
연구 배경
적당한 수의 단계에 임의의 병렬 계산을 수행할 수 있어, Deep Neural Networks (DNNs)은 speech recognition, visual object recognition과 같은 어려운 문제에 좋은 성능을 보임.
또한, 복잡한 계산 가능하고, 큰 DNN은 supervised backpropagation로 학습이 가능하며 이로 최적의 parameter를 찾아 문제를 해결할 수 있게 해줌.
이처럼 DNN은 학습이 어려운 task에서 훌륭한 성능을 갖고 있는 강력한 모델임.
그러나, DNN은 고정된 차원의 벡터를 input과 target encoder로 갖는 문제에만 적용할 수 있지만 다양한 도메인의 많은 문제들은 그렇지 않음.
ex) speech recognition, machine translation, QA와 같은 길이가 고정되지 않은 sequential problem
관련 연구
전체 input 문장을 벡터로 매핑시키는 연구 :
<Recurrent continuous translation models>,
<Learning phrase representations using RNN encoder-decoder for statistical machine translation>
attention mechanism 소개한 연구 :
<Generating sequences with recurrent neural networks>)
attention mechanism 적용한 연구 :
<Neural machine translation by jointly learning to align and translate>
seq to seq mapping 기술 :
Connectionist Sequence Classfication
→ 가정 : input과 output 사이의 monotonic alignment
Model
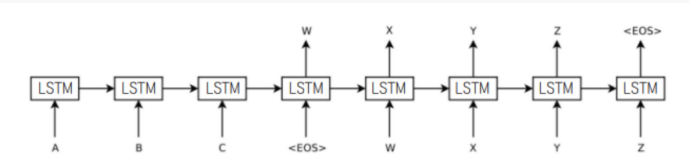
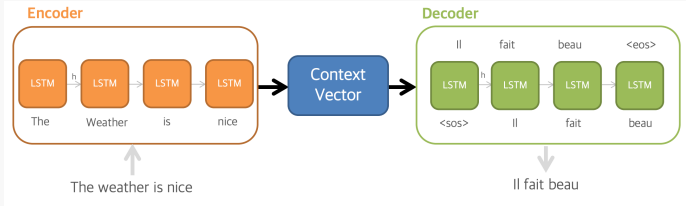
본 연구는 고정된 차원의 벡터로 input sequence를 매핑시키기 위해 여러 개의 Long Short-Term Memory (LSTM) 층을 사용함. target sequence를 만들어내는 또 다른 깊은 층의 LSTM이 decoder로 사용됨.
한 LSTM은 input sequence를 읽어 크고 고정된 차원의 벡터 표현을 얻고, 다른 LSTM은 그 벡터로부터 output sequence를 추출함.
Recurrent Neural Network(RNN) :
연속적인 순전파 신경망, input에 대해 output을 반복하며 계산
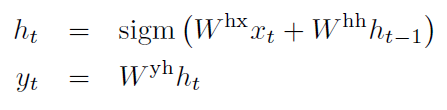
input과 output이 일정한 규칙없이 복잡하고 non-monotonic한 관계를 가진다면 적용하기 어려워짐.
→ input sequence를 RNN을 이용해 고정된 크기의 벡터로 매핑하고, 또 다른 RNN으로 벡터를 target sequence로 매핑하는 방법이 있지만, long term dependencies 때문에 RNN을 학습시키기 어려워 LSTM이 최적 !
Long Short Term Memory (LSTM) :
목표 : input sequence에 대한 output sequence의 조건부 확률을 평가하는 것
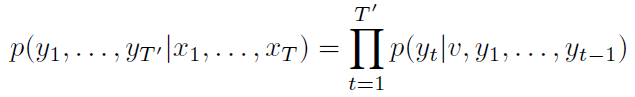
p(yt|v, y1, y2, ..., yt-1) 분포는 각 단어에 대한 softmax로 표현
훈련할 때, objective function으로 log probability가 최대화되는 방향으로 훈련을 진행함.
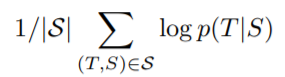
S : training set, T : 모델의 번역 결과
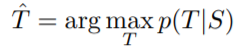
left to right beam search decoder를 이용해 가장 높은 확률의 번역을 찾아냄.
source 문장과 target 문장이 결합할 때 source 문장의 각 단어는 target 문장과 거리가 먼 단어와 연결되어 큰 minimal time lag가 발생함.
단어의 순서를 거꾸로 하는 것이 source 문장의 첫 단어와 target 문장의 첫 단어와 매우 밀접해 minimal time lag가 크게 감소함. 또한, backpropagation 과정에서 source와 target 사이의 establishing communication이 쉬워지게 됨.→ 전반적인 성능의 향상
실험 환경
WMT'14 English to French Machine Translation Task에 대해 모델을 실험함.
모델 훈련을 위해 348M개의 French word와 304M English word로 구성된 12M개의 문장을 이용함.
vector 표현에 의존적이기 때문에, 우리는 두 언어의 모든 어휘를 고정함. 포함되지 않은 단어는 <UNK> token으로 대체함.
SMT의 사용 없이 직접적으로 input 문장 번역하고, SMT baseline의 n-best에 대해 실험함.
결론
WMT’14 English to French translation task에서 5 deep LSTM(384M parameters, 8,000 dimensional state each and 80k words)로부터 단순한 left-to-right beam-search decoder 구조를 통해 34.81 BLEU score를 얻음.
SMT baseline은 33.30 BLEU score를 얻고, SMT에서 가장 점수가 높은 1,000개의 리스트를 가지고 LSTM에서 실험을 진행한 결과, 36.50 BELU score를 얻음.
얕은 LSTM보다 깊은 LSTM이 더 좋은 성능을 보임.
LSTM은 매우 긴 문장에서 어려움을 겪지 않음. 본 연구에서 긴 문장에 대해 단어의 순서를 거꾸로 넣어줬음. → short term dependencies에 대해 쉽게 최적화를 진행할 수 있음. Stochastic Gradient Decent(SGD)로 긴 문장에 대해 어려움 없이 학습함.
LSTM은 다양한 길이의 input 문장을 고정된 차원의 벡터 표현으로 매핑해줌. LSTM은 유사한 문장은 가까이 두고 그렇지 않다면 멀리 떨어뜨림.