[Efficient Estimation of Word Representation in Vector Space]
" Efficient Estimation of Word Representation in Vector Space " - Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean (2013)

본 논문에서는 ..
- 대량의 데이터로부터 단어의 질 높은 연속적인 벡터 표현을 계산하기 위해 두 개의 새로운 모델 구조 제안함.
가정 : 비슷한 단어는 가까이 있고, 단어들은 multiple degrees of similarity를 가짐.
-> 단어 사이의 선형 규칙을 보존하는 새로운 모델 구조를 개발하여 벡터 표현 연산의 정확도를 극대화 할 것임.
2. 단어 벡터의 품질을 측정하기 위해 종합적인 테스트셋을 정의함.
연구 배경
많은 NLP 분야에서는 단어를 atomic unit으로 다루어 단어 간의 유사성이라는 개념이 없음.
→ 단순, robust함. 이런 모델이 적은 데이터로 복잡한 모델보다 성능이 좋다고 관찰되어 자주 사용됨.
ex) N-gram model
one-hot encoding :
대용량 메모리 필요, 유사성 비교 불가능(코사인 유사도 계산이 불가능해짐.)
최근 머신러닝 기술의 진보로 복잡한 모델을 훈련시키는 것이 가능해졌고, 단순한 모델들의 성능을 뛰어넘음. 가장 성공적인 concept은 단어의 distributed representation임.
distributed representation :
단어를 문맥에 기반하여 표현하는 방법, 각각의 속성을 독립적인 차원으로 나타내지 않고, 우리가 정한 차원으로 대응시켜 표현하는 방식, sparse하지 않음.
관련 연구
단어를 연속적인 벡터로 표현하는 방법 연구(NNLM) :
.A neural probabilistic language model Language Modeling for Speech Recognition in Czech , Neural network based language models for higly inflective languages
Model
본 논문에서는 distributed representation에 초점을 맞추고, 모델의 계산 복잡도를 모델이 훈련하기 위해 필요했던 파라미터의 수로 정의함.
계산 복잡도 ?
O = E ×T ×Q
O : training epochs의 수, T : training set의 단어 수, Q : 각 모델에 따라 다르게 정의
모든 모델은 SGD, backpropagation으로 학습됨.
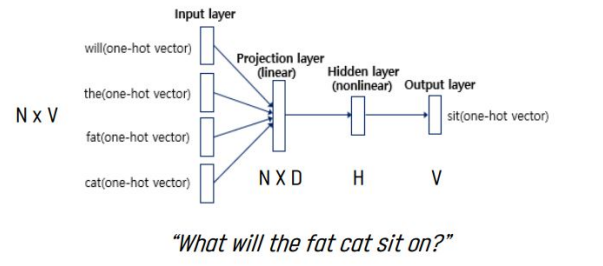
1. Feedforward Neural Net Language Model(NNLM)
Input, Projection, Hidden, Output layer로 구성됨.
Q = N × D + N × D × H + H × V (→log(V))
N : input word 개수, V : vocabulary size, D : word representation dimenstion, H : hidden layer size
시간 복잡도를 줄이기 위해 hierarchical Softmax를 사용하거나 훈련 중 un-nomalized model을 이용하기도 함.
또한, 1-of-V encoding의 단어 표현을 효과적으로 하기 위해 binary tree를 이용하여 log(V)의 크기로 scale down함.
본 논문의 모델에서는 Huffman binary Tree를 이용하여 hierarchical softmax를 사용함. 그럼에도 불구하고 N x D x H의 복잡성은 해결되지 않기에, Hidden layer를 갖지 않는 모델을 제안함.
단점 : 입력 벡터수 n이 고정, 이전 단어만 고려하고 이후에 단어는 고려하지 못함, 높은 계산 복잡도를 가짐.
2. Recurrent Net Language Model(RNNLM)
문맥의 길이를 명시해야 하는 것과 같은 NNLM의 한계를 극복하기 위해 제안됨.
projection layer가 없고, input, hidden, output layer만 있음.
Q = H × H + H × V (→log(V))
recurrent matrix가 hidden layer 그 자체와 시간 흐름의 연결을 갖고 있어 short term memory 생성을 가능케 하고, 과거의 정보는 현재 input에 기반하여 업데이트될 수 있음.
NNLM과 동일하게 hierarchical softmax를 사용하면 log(V)의 크기로 scale down됨.
단점 : 이전 단어만 고려, 높은 계산 복잡도
Parallel Training of Neural Networks
NNLM과 논문에서 제안한 DistBelief라 불리는 top of large-scale distributed framework인 몇몇 모델을 실행함.
Adagrad를 사용한 mini-batch asynchronous gradient descent 사용함.
3. New Log-linear Models
계산 복잡도를 최소화하면서 distributed representation을 학습하기 위해 두 가지 모델 구조를 제안함.
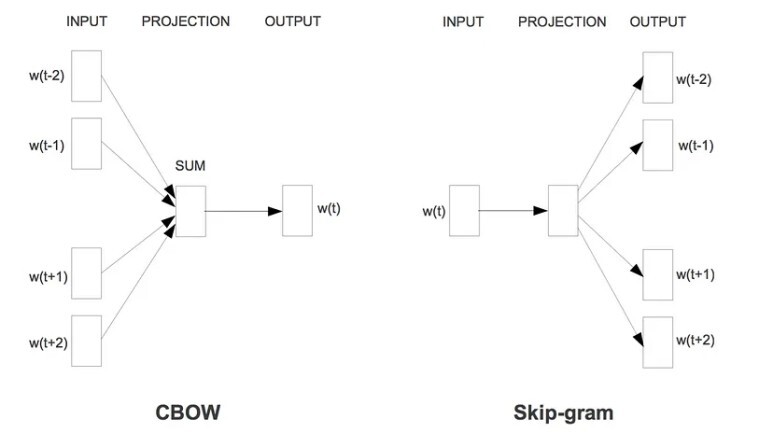
1) Continuous Bag-of-Words Model(CBOW)
연산량이 많이 소요되는 non-linear hidden layer가 제거되고, projection layer가 모든 단어에 공유되는 feedforward NNLM과 비슷함.
projection layer의 경우 activation function을 사용하지 않는 linear layer임.
단어 순서가 projection에 영향을 미치지 않아 bag-of-word 모델이라고 부름.
Q = N × D + D × log2(V)
보통의 bag-of-word 모델과는 다르게, 이것은 context의 continuous distributed representation를 사용함.(단순히 평균을 내게 됨.)
2) Continuous Skip-gram Model
CBOW와 비슷하지만, context에 기반해 현재 단어를 예측하는 대신에 같은 문장의 다른 단어에 기반한 단어의 분류를 극대화함.
현재의 단어를 연속적인 projection layer와 함께 log-linear classifier에 사용하고, 현재 단어 앞뒤의 특정 범위 안의 단어를 예측함.
Q = C × (D + D × log2(V))
C : 예측할 word와 현재 word의 maximum distance
[1, C)의 범위에서 랜덤하게 R을 뽑고, 현재 word 이전 R개, 이후 R개에 대해 예측함. 범위를 증가하면 quality는 높아지나 계산 복잡도도 증가하여 거리가 먼 단어는 훈련 세트에서 샘플링을 적게 함으로써 가중치를 줄여 나감.
실험 환경
정확도 측정 ?
성능은 단어 유사도로 측정, 이전에 가장 좋은 성능을 냈던 다른 유형의 신경망 구조와 비교함.
X = vector(“biggest”) — vector(‘big”) + vector(“small”) 로 계산할 수 있음.
cosine 거리에 의해 측정된 가장 가까운 단어를 벡터 공간에서 찾음. → “smallest”
단어 벡터의 품질을 측정하기 위해 5가지 종류의 의미론적, 9가지 종류의 구문론적 질문들을 담은 test 셋을 정의함.
매우 작은 계산 복잡도로 큰 성능 향상을 보여줌. 16억개의 단어 데이터셋으로부터 높은 품질의 단어 벡터를 배우는 데 하루보다 더 적게 걸림.
단어 벡터를 훈련하기 위해 60억 token을 포함하는 Google News corpus를 사용함. 어휘 크기는 100만으로 제한함.
많은 데이터, 높은 차원의 단어 벡터 사용 → 높은 정확도를 나타낼 것으로 예상해 3만 개의 단어로 어휘를 제한한 학습 데이터 사용함.
결론
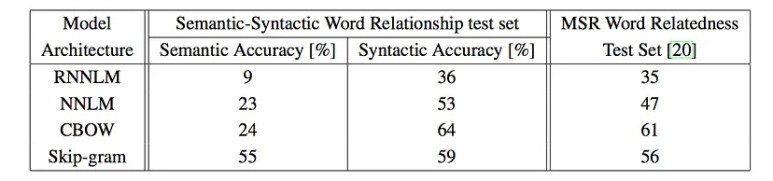
의미론적 : Skip-gram > CBOW > NNLM > RNNLM
구문론적 : CBOS > Skip-gram > NNLM > RNNLM
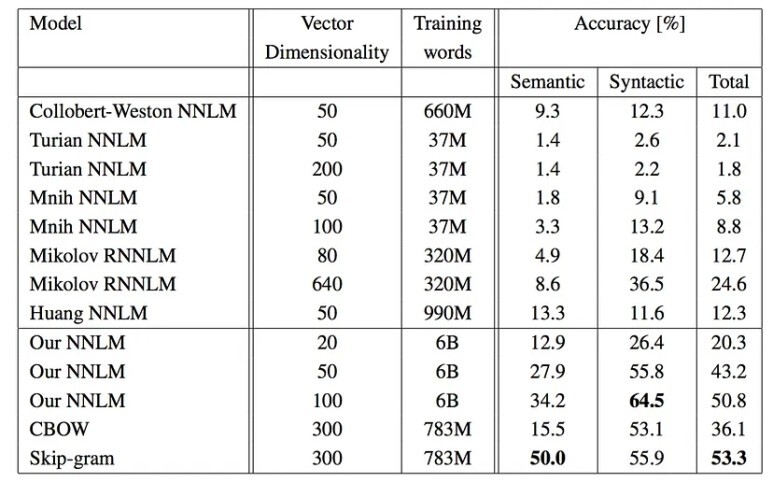
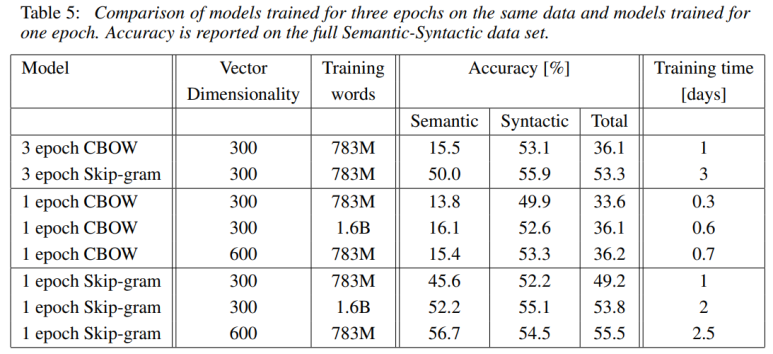
같은 데이터로 3번 훈련하는 것보다 두 배 이상의 데이터로 1번 훈련시키는 것이 더 정확도가 높고, 빠름.
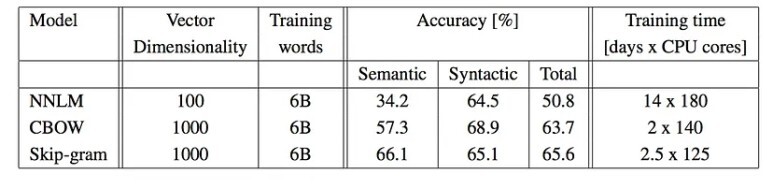
DistBelief라 불리는 분산 framework에서 다양한 모델을 실행할 때, CBOW와 Skip-gram 모델은 한 개의 machine에서 수행하는 것보다 각각에 더 가까워져 정확도가 높음.
더 많은 차원에서 더 큰 데이터를 가지고 학습된 단어 데이터가 훨씬 좋은 성능을 낼 것이며, 한 개 이상의 관계를 공급하면 정확도가 높아질 것임.