[One-Class Collaborative Filtering]
"One-Class Collaborative Filtering" - Rong Pan, Yunhong Zhou, Bin Cao, Nathan N. Liu, Rajan Lukose, Martin Scholz, Qiang Yang (2008)

Introduction
implicit feedback 데이터는 고객이 해당 아이템에 대해 명확한 피드백을 주지 않는다는 단점이 존재함.
ex) 구매 이력, 브라우징 이력, 클릭 등의 정보
→ sparse한 데이터
- negative example에 라벨 붙이기 → 시스템에 부정적인 인상 줄 수 있음.
- missing data에 대해 모두 negative examples로 처리하기 → 추천 결과가 편향될 수 있음.
이 missing data를 negative example로 잘 다룰 수 있도록 두 가지 방식을 제시함.
1. wALS
2. Sampling-based ALS
Concept
missing data를 다루는 방법은 AMAN AMAU가 CF의 일반적임.
- weighted low rank approximation을 사용함.
- 샘플링 시 missing data를 negative example로 샘플링함.
OCCF : m users, n items을 가지는 행렬 R에 대해 missing data에서 positive example를 식별하는 것이 목표임.
1) wALS

- R = (Rij)m×n ∈ [0, 1]
- W = (Wij)m×n) : 행렬 R을 low rank로 근사할 때 사용되는 weight 행렬
이때, 행렬 X = (Xij)m×n는 다음을 최소화시키는 행렬로 구함.

L(U, V)의 식에서는 과적합 방지를 위해 규제 term이 추가됨.
U, V는 각각을 고정하여 미분해서 0이 되는 U, V 값을 구함. • 이때, missing value 는 대부분은 negative으로 간주하여 0으로 처리함.

가중 체계를 3가지로 나누어 계산함.
- missing value 가 negative example 가 될 기회를 모두 equal하게 해줌.
- user가 positive example 이 많으면, missing value는 negative example이 될 확률이 높음.
- Item이 negative example 이 많으면, missing value는 negative example이 될 확률이 높음.
2) Sampling-based ALS
ALS 앙상블
- Step 1: 주어진 확률분포를 이용하여 missing value에서 negative example 들을 추출함.
- Step 2 : step1에서의 sample 바탕으로 weighting 설정 후, wALS 알고리즘으로 raitng 행렬을 추정함.
Bagging에 따라 샘플을 만들어주고 이로 각각 matrix을 재정의 한 다음 평균 내어 계산함.

샘플링 체계를 3가지로 나누어 진행함.
- 균일 무작위 샘플링은 missing data 모두 negative example로 샘플링될 동일한 확률을 가짐.
- 사용자 중심 샘플링은 사용자가 더 많은 아이템을 본 경우 그 사람이 보지 않은 아이템은 더 높은 확률로 negative가 됨.
- 아이템 중심 샘플링은 이 아이템을 적은 사용자가 보는 경우 아직 아이템을 보지 않은 사용자도 이 아이템을 안 볼 거라고 가정함.
Experiment
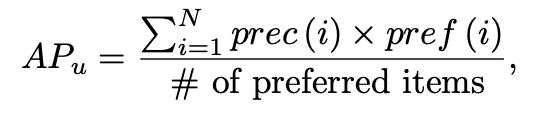
AP : 선호 item이 있는 모든 위치에서 계산된 정밀도의 평균임.

wALS의 경우 feature의 개수를 늘리면 성능이 안정적이게 증가함.


wALS, sALS의 성능이 우수함.

알파 : 부정적인 예의 비율을 제어함. 알파가 작을 때 효율적임.
Conclusion
AMAN, AMAU의 방식은 예측을 편향시킬 수 있고, wALS, Sampling based ALS은 더 나은 방향으로 이를 수정할 수 있음.