[NPA- Neural News Recommendation with Personalized Attention]
" NPA- Neural News Recommendation with Personalized Attention " - Chuhan Wu, Fangzhao Wu, Mingxiao An, Jianqiang Huang, Yongfeng Huang, Xing Xie (2019)

Introduction
사용자에 따라서 클릭할 뉴스 목록이 다르고, 같은 뉴스 안에서도 관심 있게 보는 단어가 다르다는 배경에서 시작함.
- 유저가 클릭한 모든 정보가 유저의 선호를 반영하지는 않음.
ex) “Dolphins May Have Found A Head Coach” → 스포츠에 관심있는 사람에게는 유용하나 그렇지 않은 사람에게는 유용하지 않음.
- 뉴스 제목에 각각의 단어는 다른 정보를 제공함.
ex) “Crazy Cleaning Tips That Actually Work” → Crazy > That
이전의 방법론들은 각기 다른 유저에 따라 뉴스, 단어의 다른 informativeness(개별 선호)를 반영해 모델을 구성하지 못함.
→ 이전 모델들은 고정된 attention 쿼리 벡터를 사용해 유저의 선호를 나타내기에 적합하지 않았음.
NPA(neural approach with personalized attention)을 제시함.
→ user ID 임베딩 벡터를 쿼리 벡터로 사용하여 개인의 선호를 반영할 수 있도록 news(모든 뉴스 제목, word level), user(클릭한 뉴스, news level)을 나타내는 모델을 CNN 구조로 구성함.

Model

- News Encoder
word sequence of the news Di = [w1, …., wM] → sequence of vector E^w = [e1, …., eM]
M : the number of words in the news title
word embedding matrix W_e R^VxD
V : the vocabulary size
D : the dimension of word embedding vectors
- word-level personalized attention network
key : 각각의 단어 임베딩에 대한

CNN은 local 정보를 포착하는 효과적인 신경망 구조를 가져 뉴스 제목 내 어느 단어가 유용한지 포착함.
e : the concatenation of the word embeddings from the position (i-k) to (i+k)
F_w R^Nf X (2k+1)D / b_w R^Nf : parameters of the CNN filters
N_f : the number of CNN filter
2k+1 : window size
ReLU : non-linear function for activation
query : 한 유저에 대한
e_u : 임베딩된 유저의 ID → 사용자마다 다른 사용자 선호 쿼리를 학습해 선호도 고려 가능해짐.
V_w, v_w : parameter

weight of the ith words
W_p, b_p : projection parameter
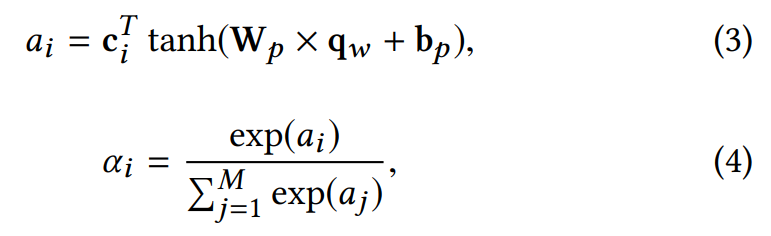
모든 뉴스 제목에 대해 news encoder를 적용함.
output

- User Encoder
클릭한 뉴스의 표현을 나타내기 위해 사용함.
“10 tips for cooking” > “It will be Rainy next week”
- news-level personalized attention network
key : 유저가 클릭한 뉴스에 대해 CNN, word-level Personalized attention을 통과한 후에 만들어진 각각의 r 벡터들
query : 한 유저에 대한

weight of ith news

output

- Click Prediction
각 candidate news에 대해 클릭 점수를 예측하는데 사용됨.
클릭한 뉴스는 매우 적음 → positive, newgative news sample는 매우 불균형함.
→ nagative sampling : 1개의 positive(클릭한 뉴스), K개의 negative
news-level personalized attention nework로 얻어진 u벡터와 각각의 ri벡터를 내적해 K+1개의 샘플링된 뉴스에 대해 클릭 점수를 예측함.


S : the set of the positive training samples
Experiment
데이터셋 : MSN News의 4주 간 유저 로그 데이터
Q1. NPA의 성능

neural network : CNN, DSSM, NPA
negative sampling : DSSM, NPA
attention : DFM, DKN, NPA

negative sampling으로 계산 비용 줄어듦. K개만큼 샘플링

모델을 학습시킨 train 데이터와 가장 가까운 첫째 날의 성능이 가장 좋음.
시간이 흐를수록 성능이 낮아지는 것은 뉴스 데이터의 특징이 시간에 민감함을 의미함.
셋째 날부터는 안정적인 그래프를 보이면서 시간의 흐름에 robust함을 파악할 수 있음.
→ 제시한 모델이 overfit 되지 않고 '유저 선호도와 뉴스 토픽에 기반한 개인화된 추천'을 해줌을 의미함.
Q2. Personalized Attention

w attention > w/o attention
Personalized attention이 가장 우수
word, news 같이 사용하는 것이 가장 우수
Q3. Negative sampling


Q4. Hyperparameter (Negative Sampling Ratio)

k가 올라갈수록 성능 올라가지만 임계치 넘어서면 성능 오히려 내려감. 적당한 값을 찾을 필요가 있음.
Conclusion

- Personalized Attention mechanism
UserID 임베딩 벡터를 활용한 사용자 선호 쿼리를 word-level attention & news-level attention에 적용함.
→ 서로 다른 사용자는 집중해서 읽는 단어와 뉴스가 다르다는 것을 추천에 반영하도록 함.
- News representation model (word-level attention)
CNN, Personalized attention을 이용하여 제목을 단어 임베딩하여 news representation을 학습함.
- User representation model (news-level attention)
Personalized attention을 이용하여 클릭한 뉴스에 대해 News representation model을 적용한 벡터에 대해 user representation을 학습함.